

DeepLearningのプログラムは、ほとんどがPythonで書かれる場合が多いのですが、画像入力やGUI部分をプログラムしたいとなると、やっぱりC#で組みたい!
ということで、学習まではPythonで行い、学習結果をONNXに保存し、ONNXをC#から読み込んでC#で推論を行う方針で、いろいろ調べてみたのですが、分からない部分もボロボロと...
とりあえず、出来た事のメモです。
作成したプログラムのイメージ
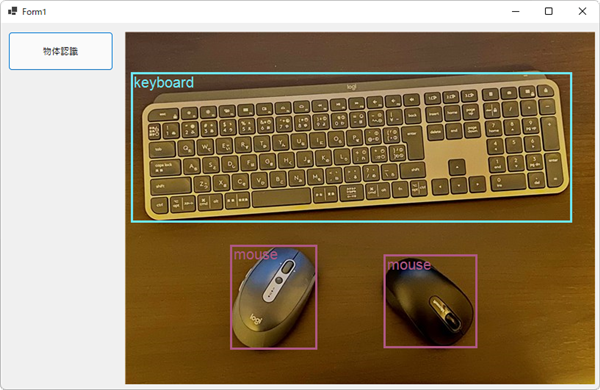

今回は.NET Coreを使って作成していますが、.NET Frameworkでも大丈夫です。
PyTorchで既存モデルをONNXファイルに保存
今回は、画像認識モデル(Object Detection)をONNXファイルに保存するサンプルです。
入力画像サイズや出力の名前を使用するモデルに合わせる必要があります。
import torch
import torchvision
# 入力画像サイズ(N, C, H, W)
x = torch.randn(1, 3, 480, 640)
# 学習済みモデル
# 参考 https://pytorch.org/vision/main/models.html#object-detection-instance-segmentation-and-person-keypoint-detection
model = torchvision.models.detection.fasterrcnn_mobilenet_v3_large_320_fpn(pretrained=True)
# ONNXファイルに保存
# 参考 https://pytorch.org/docs/stable/onnx.html
torch.onnx.export(
model, # ニューラルネットワークモデル
x, # 入力データ
'fasterrcnn_mobilenet_v3_large_320_fpn.onnx', # ONNXファイル名
opset_version=11, # ONNXバージョン
input_names = ['input'], # 入力の名前
output_names = ["boxes", "labels", "scores"] # 出力の名前
)input_names と output_names の指定は省略可能です。
C#でONNXファイルを読み込み、推論を行う方法
C#でONNXを扱えるライブラリは、いくつかあるようなのですが、今回は、マイクロソフトのOnnxRuntimeを使いました。
フォームにはボタン(button1)とピクチャボックス(pictureBox1)のみを配置しています。
使用には、NuGetでMicrosoft.ML.OnnxRuntimeを追加する必要があります。
分かっていない部分
以下は、私が分かっていない部分なので、出来るかも?しれません。
- OnnxRuntimeで読み込めるONNXのバージョンは10まで?らしいのですが、PythonでONNXのバージョンを10で保存できない。
ニューラルネットワークのモデルにも依存すると思いますが、詳細は分からず... - ONNXファイルに保存するとき、ワーニングがいっぱい出てる。
- 自前でモデルの学習を行うと、C#側で正しく推論できない。
- C#でGPUを使った推論方法が分からない。
- C#で画像をテンソル(floatの一次元配列)に変える部分は自作しましたが、下記のページを見ても、いまいちわからず。
https://docs.microsoft.com/ja-jp/dotnet/machine-learning/tutorials/object-detection-onnx
参考
https://pytorch.org/vision/main/models.html#object-detection-instance-segmentation-and-person-keypoint-detection
https://pytorch.org/docs/stable/onnx.html
https://docs.microsoft.com/ja-jp/windows/ai/windows-ml/tutorials/pytorch-convert-model
https://docs.microsoft.com/ja-jp/windows/ai/windows-ml/get-started-uwp
https://docs.microsoft.com/ja-jp/dotnet/machine-learning/tutorials/object-detection-onnx