ここでは、ある程度Deep Learningの概要やPythonについて勉強し、実際にPyTorchを使ってプログラムを組みたい人向けを想定しています。(ほぼ自分用、備忘録です)
MNISTの0~9の手書き文字画像の分類は、DeepLearningにおけるHellow World的な存在ですが、DeepLearningの画像データや正解ラベルも簡単に入手できるので、最初にプログラムを行うのには、とても便利です。
DeepLearningのプログラムを1つ作っておけば、他に流用できる部分も多いので、まずは、このMNISTをやってみたいと思います。
ここでは、Deep Learning処理の概念的な理解を重視して、ニューラルネットワーク部分はシンプルにしました。
サンプルプログラム
まずは、いきなりMNISTの0~9の手書き文字画像分類のサンプルプログラムです。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
#----------------------------------------------------------
# ハイパーパラメータなどの設定値
num_epochs = 10 # 学習を繰り返す回数
num_batch = 100 # 一度に処理する画像の枚数
learning_rate = 0.001 # 学習率
image_size = 28*28 # 画像の画素数(幅x高さ)
# GPU(CUDA)が使えるかどうか?
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#----------------------------------------------------------
# 学習用/評価用のデータセットの作成
# 変換方法の指定
transform = transforms.Compose([
transforms.ToTensor()
])
# MNISTデータの取得
# https://pytorch.org/vision/stable/generated/torchvision.datasets.MNIST.html#torchvision.datasets.MNIST
# 学習用
train_dataset = datasets.MNIST(
'./data', # データの保存先
train = True, # 学習用データを取得する
download = True, # データが無い時にダウンロードする
transform = transform # テンソルへの変換など
)
# 評価用
test_dataset = datasets.MNIST(
'./data',
train = False,
transform = transform
)
# データローダー
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size = num_batch,
shuffle = True)
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size = num_batch,
shuffle = True)
#----------------------------------------------------------
# ニューラルネットワークモデルの定義
class Net(nn.Module):
def __init__(self, input_size, output_size):
super(Net, self).__init__()
# 各クラスのインスタンス(入出力サイズなどの設定)
self.fc1 = nn.Linear(input_size, 100)
self.fc2 = nn.Linear(100, output_size)
def forward(self, x):
# 順伝播の設定(インスタンスしたクラスの特殊メソッド(__call__)を実行)
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#----------------------------------------------------------
# ニューラルネットワークの生成
model = Net(image_size, 10).to(device)
#----------------------------------------------------------
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
#----------------------------------------------------------
# 最適化手法の設定
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate)
#----------------------------------------------------------
# 学習
model.train() # モデルを訓練モードにする
for epoch in range(num_epochs): # 学習を繰り返し行う
loss_sum = 0
for inputs, labels in train_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# optimizerを初期化
optimizer.zero_grad()
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss = criterion(outputs, labels)
loss_sum += loss
# 勾配の計算
loss.backward()
# 重みの更新
optimizer.step()
# 学習状況の表示
print(f"Epoch: {epoch+1}/{num_epochs}, Loss: {loss_sum.item() / len(train_dataloader)}")
# モデルの重みの保存
torch.save(model.state_dict(), 'model_weights.pth')
#----------------------------------------------------------
# 評価
model.eval() # モデルを評価モードにする
loss_sum = 0
correct = 0
with torch.no_grad():
for inputs, labels in test_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss_sum += criterion(outputs, labels)
# 正解の値を取得
pred = outputs.argmax(1)
# 正解数をカウント
correct += pred.eq(labels.view_as(pred)).sum().item()
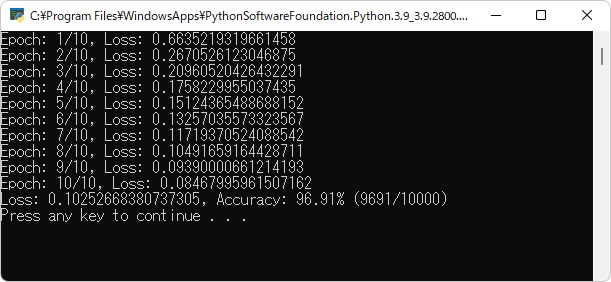
print(f"Loss: {loss_sum.item() / len(test_dataloader)}, Accuracy: {100*correct/len(test_dataset)}% ({correct}/{len(test_dataset)})")
実行結果
使用モジュールの定義
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transformstorchは、もちろんPyTorch用のモジュールです。
torchvisionはPyTorchの画像を使ったDeepLearning処理のための補助モジュールで、データセットの作成や、画像データからテンソルへの変換、画像の水増しなどを行います。
パラメータの設定
#----------------------------------------------------------
# ハイパーパラメータなどの設定値
num_epochs = 10 # 学習を繰り返す回数
num_batch = 100 # 一度に処理する画像の枚数
learning_rate = 0.001 # 学習率
image_size = 28*28 # 画像の画素数(幅x高さ)
# GPU(CUDA)が使えるかどうか?
device = 'cuda' if torch.cuda.is_available() else 'cpu'エポック数(繰り返し回数)、学習率など、設定を変更するパラメータは、一か所にまとめておくと変更しやすいので便利です。
データセット、データローダーの作成
#----------------------------------------------------------
# 学習用/評価用のデータセットの作成
# 変換方法の指定
transform = transforms.Compose([
transforms.ToTensor()
])
# MNISTデータの取得
# https://pytorch.org/vision/stable/generated/torchvision.datasets.MNIST.html#torchvision.datasets.MNIST
# 学習用
train_dataset = datasets.MNIST(
'./data', # データの保存先
train = True, # 学習用データを取得する
download = True, # データが無い時にダウンロードする
transform = transform # テンソルへの変換など
)
# 評価用
test_dataset = datasets.MNIST(
'./data',
train = False,
transform = transform
)
# データローダー
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size = num_batch,
shuffle = True)
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size = num_batch,
shuffle = True)データセットとは、推論を行うためのデータとラベル(正解データ)のセットの集まりです。
学習時に用いる画像と評価時に用いる画像を別の画像にするため、学習用のデータセットは train = True
評価用のデータセットは train = False に設定します。
データローダーは、学習時にデータセットの中からbatch_size個分だけ、まとめてデータを取り出します。
後述する学習時のfor分の部分で、以下のように書いている部分が、データローダーの中からデータとラベルをbatch_size個ずつ取り出している部分となります。
for inputs, labels in train_dataloader:
: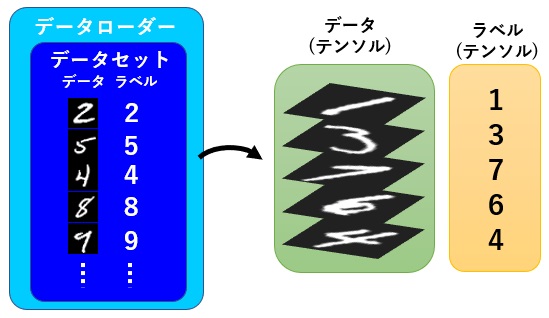
このデータを取り出す際に、データを拡大、縮小、移動などを行い、見かけ上のデータ数を増やす水増しと言われる処理や、データを並び替えて値を0~1の値に収まるように変換し、テンソルと呼ばれるデータ形式に変更します。
”テンソル”という言葉が出てくると、いきなり難しくも感じるのですが、プログラム的に言うと、ただの多次元配列となります。
画像データの場合、幅(W)、高さ(H)、色(C)と置くと、モノクロ画像の場合[H、W]の2次元配列となり、カラーの場合は[H, W, C]の3次元配列となりますが、これにバッチ数のNを追加し、
[N, C, H, W]の順番の4次元配列に格納されたデータがテンソルとなります。
今回は、手書き文字のデータセットを用いましたが、他にも既存のデータセットがいろいろあるので、こちらを参照ください。

また、既存のデータセットではなく、自作のデータセットを作成することも可能ですが、これについては、別途記事にしたいと思います。
ニューラルネットワークの作成
#----------------------------------------------------------
# ニューラルネットワークモデルの定義
class Net(nn.Module):
def __init__(self, input_size, output_size):
super(Net, self).__init__()
# 各クラスのインスタンス(入出力サイズなどの設定)
self.fc1 = nn.Linear(input_size, 100)
self.fc2 = nn.Linear(100, output_size)
def forward(self, x):
# 順伝播の設定(インスタンスしたクラスの特殊メソッド(__call__)を実行)
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#----------------------------------------------------------
# ニューラルネットワークの生成
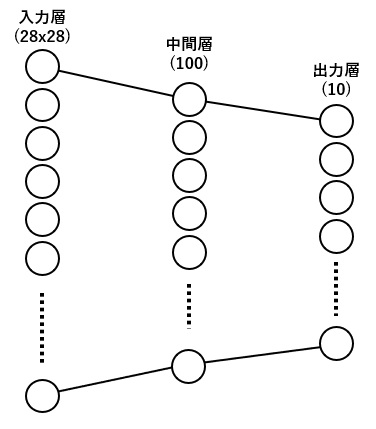
model = Net(image_size, 10).to(device)今回は入力に画像データ全画素数(28×28)の784個入力で、全結合(出力100個)→シグモイド→全結合(出力10個)→ログソフトマックス というとてもシンプルな物にしました。
ニューラルネットワークを作成するには、nn.Moduleクラスを継承し、ニューラルネットワークのクラスを作成します。ここではクラス名を Net としましたが、クラス名についての制限はありません。
通常、作成するクラスのコンストラクタ(__init__)の部分で、各層で使われる処理(ここでは全結合のLinear)のクラスのインスタンスにより、入力サイズや出力サイズ、各種オプション設定を行います。
順伝播される処理の流れは forwardメソッド(メソッド名はforwardであること)により定義します。
例えば
x = self.fc1(x)の部分では、コンストラクタの部分で定義したLinearクラスのインスタンス(self.fc1)にカッコ() を付けて、入力データである x を引数のように渡していますが、この書き方はPython特有で、実際には Linearクラスの
__call__メソッドが呼ばれます。
このような書き方を特殊メソッドというのですが、詳細は下記ページを参照ください。
(参考)

損失関数の定義
#----------------------------------------------------------
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
#----------------------------------------------------------
# 学習中にて
# 損失(出力とラベルとの誤差)の計算
loss = criterion(outputs, labels)損失関数は、ニューラルネットワークの出力と、ラベルとの誤差を計算します。
今回、損失関数に用いているCrossEntropyLossは損失関数の中では少し特殊で、複数の出力の値とラベル1つの値との誤差を計算しています。
よくあるのは、出力の数とラベルの数は同じ数で、下図のようなイメージとなります。
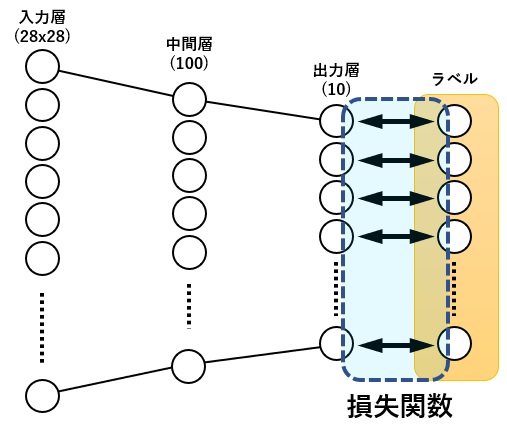
学習の工程では、この誤差が小さくなるよう、各層の重みの調整を繰り返し行います。
(参考)

最適化手法の定義
#----------------------------------------------------------
# 最適化手法の設定
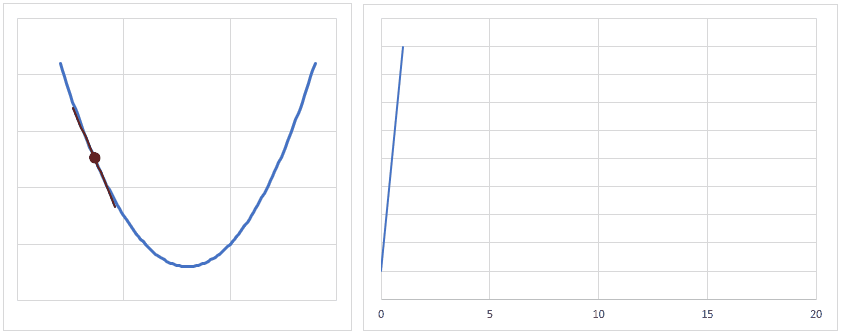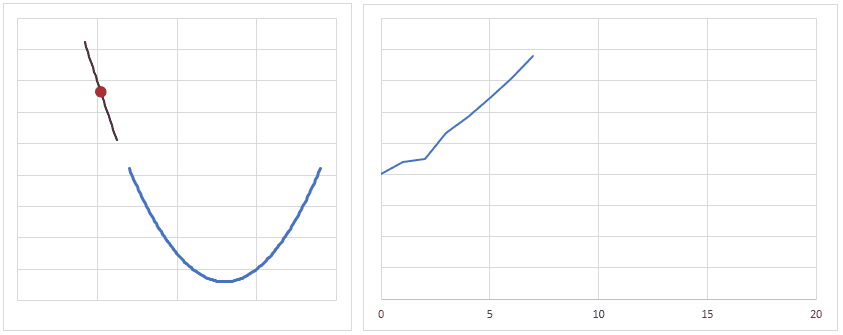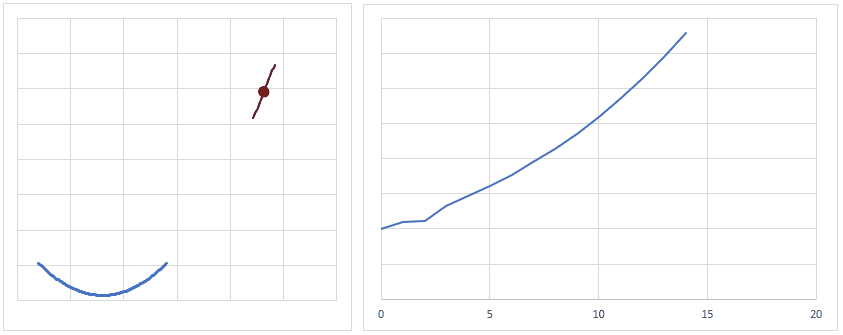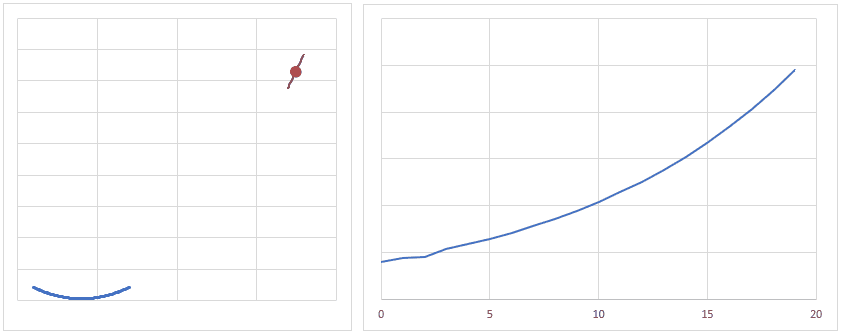
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate) 最適化関数は、損失関数から求めた勾配(損失関数を求める重みで偏微分し、現時点の重みを代入した値)を元に、最適値へ近づけるための手法です。
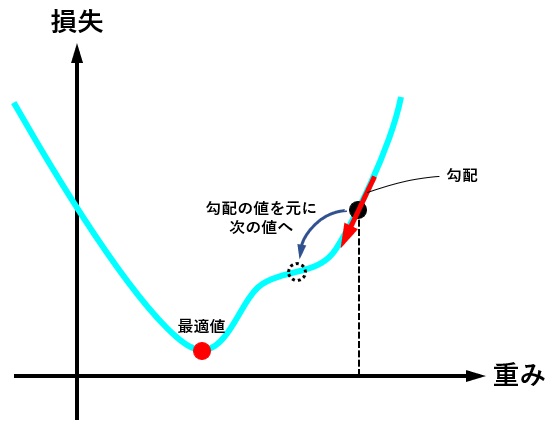
下図は、重みの値が最適値に更新されるときのイメージですが、現時点の重みが最適値から離れている場合は勾配(接線の傾き)は大きくなり、より大きく最適値に近づくように重みの値が更新されます。
逆に、重みの値が最適値に近づくと、勾配が小さくなり、重みの更新量も少なくなります。
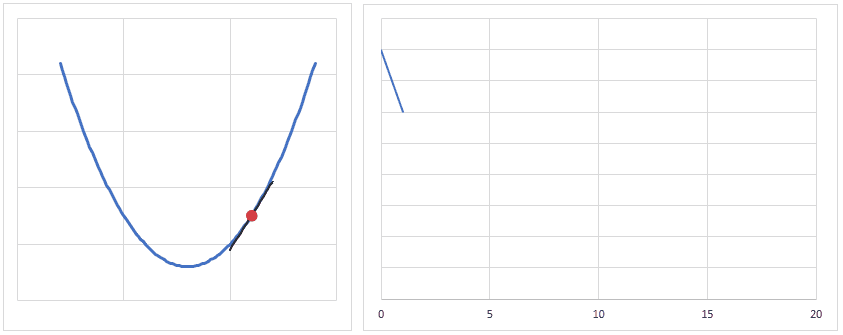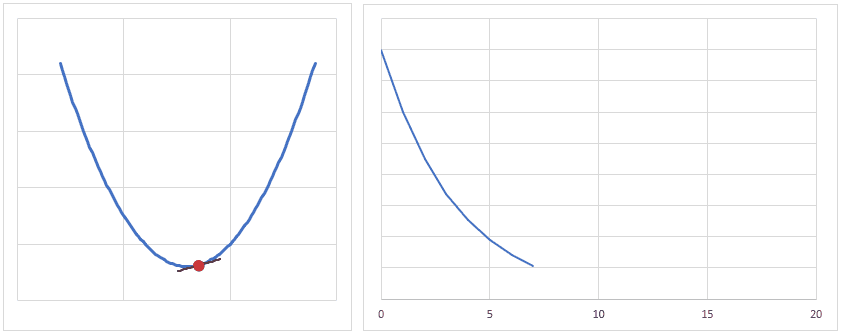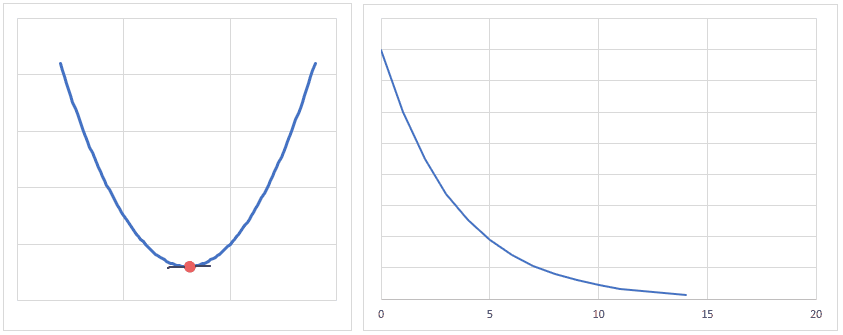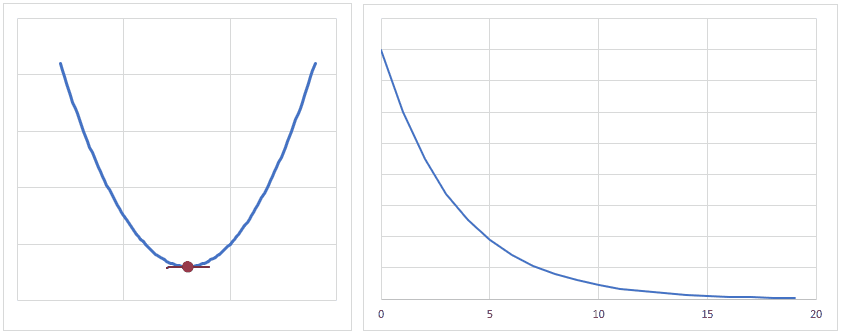
学習率(lr)は、値が大きいと早く最適値へ近づくようになりますが、大きすぎると逆に最適値から離れてしまうので、注意が必要です。
とりあえずは lr = 0.001 ぐらいから始めてみるといいかも?しれません。
(参考)

学習
#----------------------------------------------------------
# 学習
model.train() # モデルを訓練モードにする
for epoch in range(num_epochs): # 学習を繰り返し行う
loss_sum = 0
for inputs, labels in train_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# optimizerを初期化
optimizer.zero_grad()
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss = criterion(outputs, labels)
loss_sum += loss
# 勾配の計算
loss.backward()
# 重みの更新
optimizer.step()
# 学習状況の表示
print(f"Epoch: {epoch+1}/{num_epochs}, Loss: {loss_sum.item() / len(train_dataloader)}")
# モデルの重みの保存
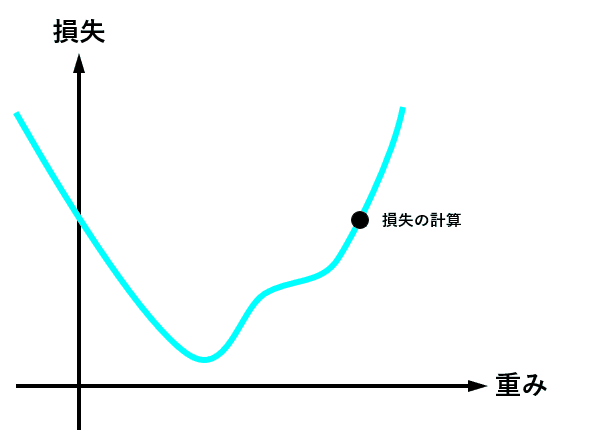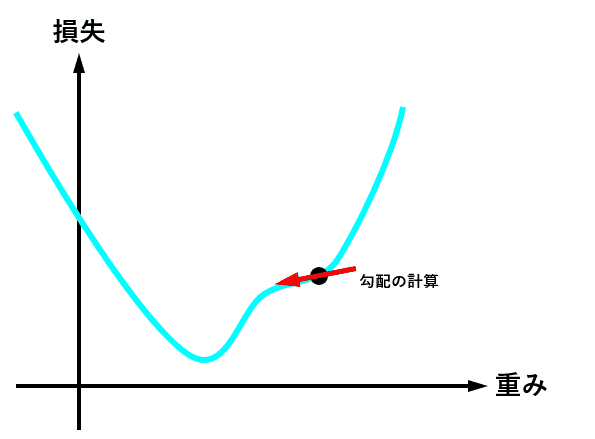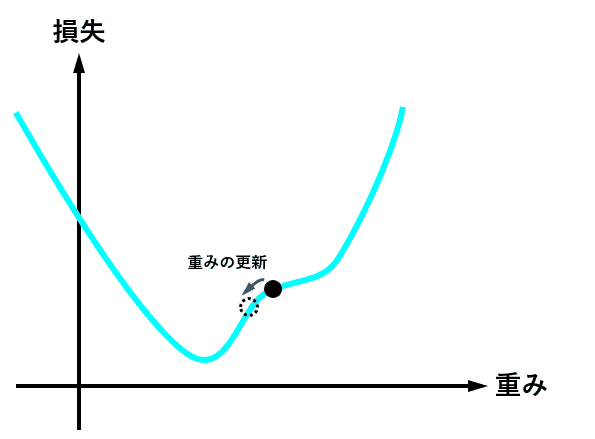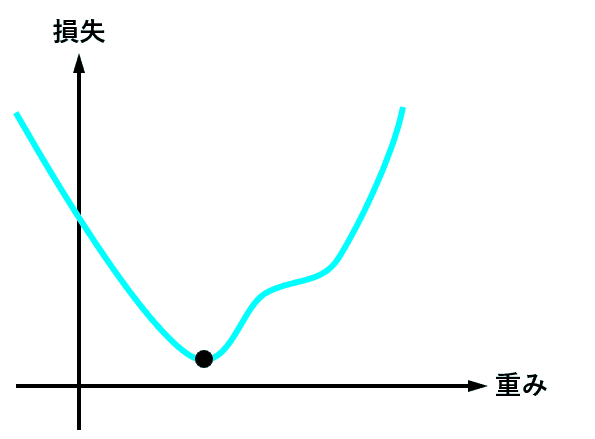
torch.save(model.state_dict(), 'model_weights.pth')学習の工程は、各重みを最適値へ近づけるため、for分で繰り返し処理を行うのですが、学習の部分で重要な部分を抜き出すと
# optimizerを初期化
optimizer.zero_grad()
# 損失(出力とラベルとの誤差)の計算
loss = criterion(outputs, labels)
# 勾配の計算
loss.backward()
# 重みの更新
optimizer.step()の繰り返しとなっています。
この繰り返しのイメージは、こんな感じ↓です。
評価
#----------------------------------------------------------
# 評価
model.eval() # モデルを評価モードにする
loss_sum = 0
correct = 0
with torch.no_grad():
for inputs, labels in test_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss_sum += criterion(outputs, labels)
# 正解の値を取得
pred = outputs.argmax(1)
# 正解数をカウント
correct += pred.eq(labels.view_as(pred)).sum().item()
print(f"Loss: {loss_sum.item() / len(test_dataloader)}, Accuracy: {100*correct/len(test_dataset)}% ({correct}/{len(test_dataset)})")
今回は、0~9までの画像分類を行っているので、出力(output)は10個のテンソルデータとなり、この10個のデータの配列中、値が最大となる値のインデックス番号が、推測された数字の値(0~9)と一致するようになっています。
まとめ
ここで紹介しているサンプルは、Deep Learningをするはしめの一歩として、もろもろシンプルにしています。
ニューラルネットワークはシンプルだし、学習中の過学習の評価用に検証データも欲しいし、画像も表示したい。
と、いろいろ不足しているかと思いますが、おいおい記事にしたいと思います。
PyTorchそのものは、画像を使ったDeepLearningで行われる、画像の分類、認識、領域分割専用に作られている訳では無いので、最初のハードルが少々高く感じます。
さらに、画像データをニューラルネットワークに流すには、画像データをテンソルに変換して。。
とかいうと、なぜか難しく感じてしまいます。
テンソルも、ただの配列なのに、numpyのndarrayは、比較的容易に受け入れていたのに、なぜ、PyTorchのテンソルは受け入れ難く感じるのか??
本記事では、その辺のハードルが少しでも下がって感じてもらえると幸いです。

コメント