Deep Learningを勉強すると、とにかく分からないバックプロパゲーション。
やっていることは、入力の値に重みやバイアスを掛けて構築されるニューラルネットワークの出力値が目標値に近づくように重みやバイアスを調整するいわゆる学習の工程ですが、行列の計算式や∑がつらつら出てくるので、ぜんぜん理解できない。。
しかし、下図のよく出てくるニューラルネットワークの図を見ていると、yの値は入力値xの値と未知数のw、bの値からなっており、出力値と目標値の差の二乗の合計の値が最小になるようにw,bの値を求めてやればいい。
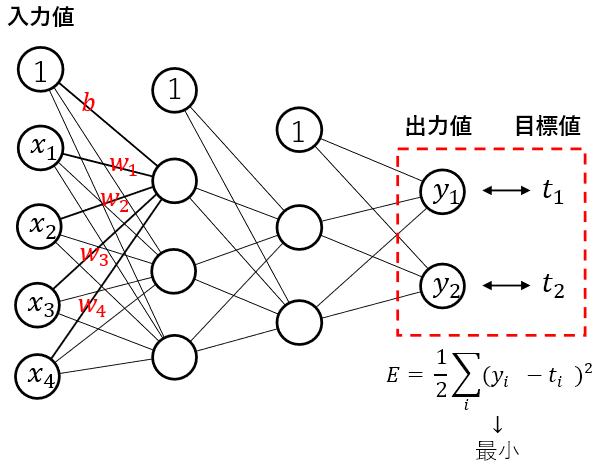
この出力値と目標値の差の二乗の合計の値が最小になるにっていう響き、何か聞いたことがあるぞ! そう最小二乗法!!!
最小二乗法では二乗誤差の合計が最小となるように、二乗誤差の合計の式に関して
未知数の偏微分 = 0
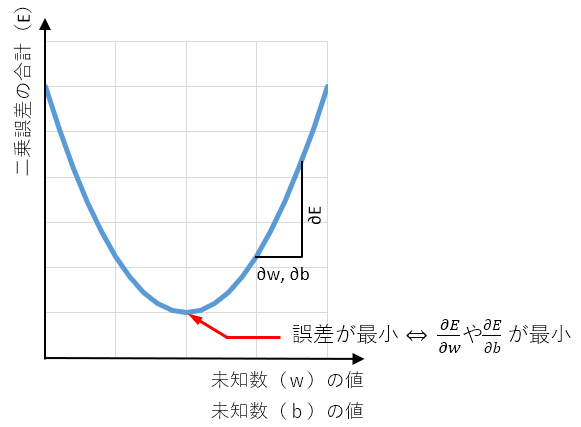
として、未知数を求めますが、同じようなノリで、二乗誤差の合計の式に関して未知数の偏微分の値が0に近づくように未知数を更新してやる処理がバックプロパゲーションとなります。(この説明だけでは、バック感が無いのですが、バック感が出てくるのは最後のほうの説明で。)
未知数の偏微分の値を0にするのが最小二乗法ですが、未知数の偏微分の値が小さくなるように未知数を更新しながら誤差を小さくする手法が勾配降下法となります。
ここからが本題です。
通常の最小二乗法と比べ、未知数が多く、特に中間層の重み(w)やバイアス(b)を求める方法が私にはなかなか理解できなかったのですが、基本はやはり二乗誤差の合計が最小となるように二乗誤差の合計を未知数で偏微分し、誤差が最小になるように未知数を更新します。
$$w\leftarrow w-\eta \frac { \partial E }{ \partial w } $$
$$b\leftarrow b-\eta \frac { \partial E }{ \partial b } $$
$$\eta は学習率で0.01など$$
ここで、各層の重みやバイアス、活性化関数を表現できるように、定番のニューラルネットワークの図を下図のように書き換えます。
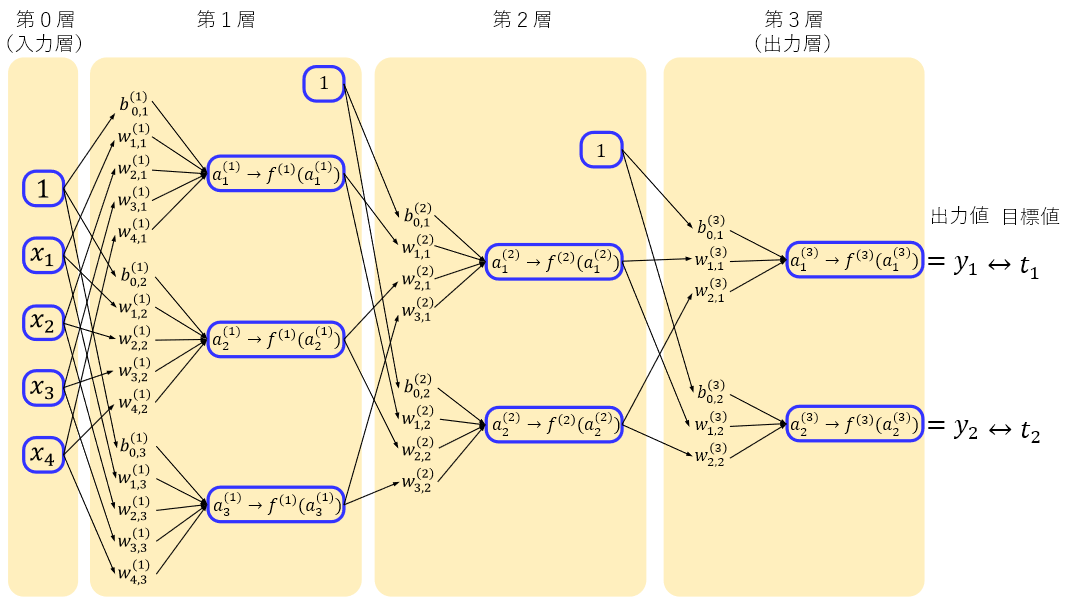
上図の記号の意味は

のように、記号の右上にカッコ付きで層番号、右下に入力ノード番号、出力ノード番号を表します。
aは入力値と重みを掛けて合計した値で、例えば、
$${ a }_{ 1 }^{ (1) }=1 { b }_{ 0,1 }^{ (1) }+{ x }_{ 1 } { w }_{ 1,1 }^{ (1) }+{ x }_{ 2 } { w }_{ 2,1 }^{ (1) }+{ x }_{ 3 } { w }_{ 3,1 }^{ (1) }+{ x }_{ 4 } { w }_{ 4,1 }^{ (1) }$$
$${ a }_{ 1 }^{ (2) }=1 { b }_{ 0,1 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 1 }^{ (1) } \right) { w }_{ 1,1 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 2 }^{ (1) } \right) \ { w }_{ 2,1 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 2 }^{ (1) } \right) { w }_{ 3,1 }^{ (2) }$$
その他の記号は
b:バイアス
w:重み
f:各層の活性化関数
とします。
順伝播
順伝播を少々面倒ですが、すべて書き出してみます。
第1層
$${ a }_{ 1 }^{ (1) }=1 { b }_{ 0,1 }^{ (1) }+{ x }_{ 1 } { w }_{ 1,1 }^{ (1) }+{ x }_{ 2 } { w }_{ 2,1 }^{ (1) }+{ x }_{ 3 } { w }_{ 3,1 }^{ (1) }+{ x }_{ 4 } { w }_{ 4,1 }^{ (1) }$$
$${ a }_{ 2 }^{ (1) }=1 { b }_{ 0,2 }^{ (1) }+{ x }_{ 1 } { w }_{ 1,2 }^{ (1) }+{ x }_{ 2 } { w }_{ 2,2 }^{ (1) }+{ x }_{ 3 } { w }_{ 3,2 }^{ (1) }+{ x }_{ 4 } { w }_{ 4,2 }^{ (1) }$$
$${ a }_{ 3 }^{ (1) }=1 { b }_{ 0,3 }^{ (1) }+{ x }_{ 1 } { w }_{ 1,3 }^{ (1) }+{ x }_{ 2 } { w }_{ 2,3 }^{ (1) }+{ x }_{ 3 } { w }_{ 3,3 }^{ (1) }+{ x }_{ 4 } { w }_{ 4,3 }^{ (1) }$$
活性化関数後は
$${ f }^{ (1) }\left( { a }_{ 1 }^{ (1) } \right)$$
$${ f }^{ (1) }\left( { a }_{ 2 }^{ (1) } \right)$$
$${ f }^{ (1) }\left( { a }_{ 3 }^{ (1) } \right)$$
第2層
$${ a }_{ 1 }^{ (2) }=1{ b }_{ 0,1 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 1 }^{ (1) } \right) { w }_{ 1,1 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 2 }^{ (1) } \right) { w }_{ 2,1 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 3 }^{ (1) } \right) { w }_{ 3,1 }^{ (2) }$$
$${ a }_{ 2 }^{ (2) }=1{ b }_{ 0,2 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 1 }^{ (1) } \right) { w }_{ 1,2 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 2 }^{ (1) } \right) { w }_{ 2,2 }^{ (2) }+{ f }^{ (1) }\left( { a }_{ 3 }^{ (1) } \right) { w }_{ 3,2 }^{ (2) }$$
活性化関数後は
$${ f }^{ (2) }\left( { a }_{ 1 }^{ (2) } \right)$$
$${ f }^{ (2) }\left( { a }_{ 2 }^{ (2) } \right)$$
第3層
$${ a }_{ 1 }^{ (3) }=1{ b }_{ 0,1 }^{ (3) }+{ f }^{ (2) }\left( { a }_{ 1 }^{ (2) } \right) { w }_{ 1,1 }^{ (3) }+{ f }^{ (2) }\left( { a }_{ 2 }^{ (2) } \right) { w }_{ 2,1 }^{ (3) }$$
$${ a }_{ 2 }^{ (3) }=1{ b }_{ 0,2 }^{ (3) }+{ f }^{ (2) }\left( { a }_{ 1 }^{ (2) } \right) { w }_{ 1,2 }^{ (3) }+{ f }^{ (2) }\left( { a }_{ 2 }^{ (2) } \right) { w }_{ 2,2 }^{ (3) }$$
活性化関数後は
$${ f }^{ (3) }\left( { a }_{ 1 }^{ (3) } \right)$$
$${ f }^{ (3) }\left( { a }_{ 2 }^{ (3) } \right)$$
逆伝播
逆伝播に関しては誤差の関数
$$E=\frac { 1 }{ 2 } \sum _{ i }^{ }{ { ({ y }_{ i }-{ t }_{ i }) }^{ 2 } } $$
について、未知数であるwやbで偏微分を行い、次の式のように値を更新すればよいので、未知数の偏微分が求まれば、値も勾配降下法で求めることができます。
$$w\leftarrow w-\eta \frac { \partial E }{ \partial w } $$
$$b\leftarrow b-\eta \frac { \partial E }{ \partial b } $$
第3層
とりあえずEを未知数の \({ w }_{ 1,1 }^{ (3) }\) で偏微分してみたいと思います。
Eを\({ w }_{ 1,1 }^{ (3) }\)で偏微分するという事は、Eの式中の\({ w }_{ 1,1 }^{ (3) }\)が含まれる項に関してだけ微分すればよいので、下図の赤い部分に関してだけ偏微分していきます。
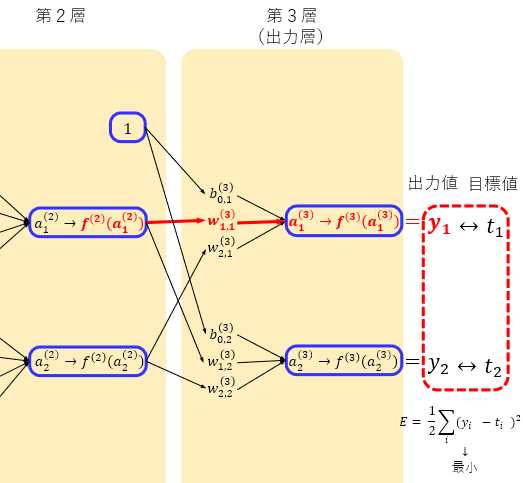

同様にバイアスの \({ b }_{ 0,1 }^{ (3) }\) で偏微分してみます。

他の未知数もまとめると
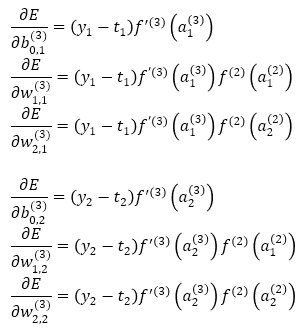
となります。
第2層
2層目の未知数 \({ w }_{ 1,1 }^{ (2) }\) に関して偏微分するには \({ w }_{ 1,1 }^{ (2) }\) に関連する項は下図の赤い部分となり、少し広範囲になります。
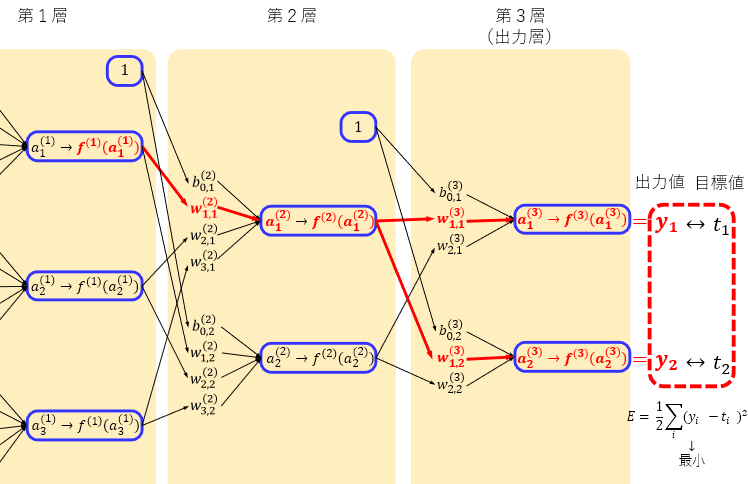

バイアスも同様に偏微分すると

となり、まとめると
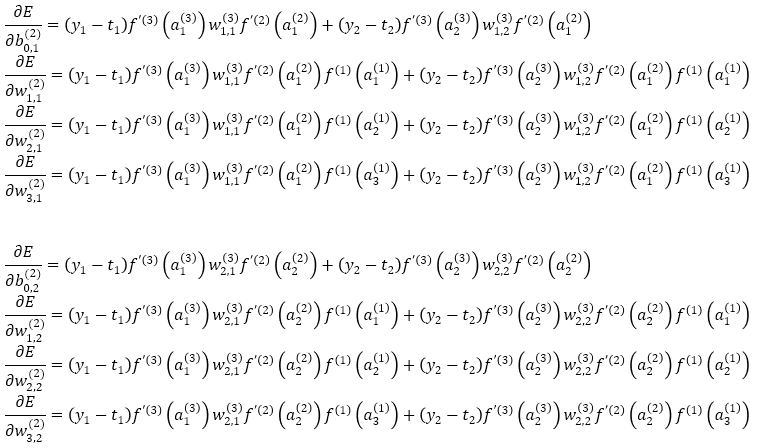
となります。
第1層は??
もう大変なので、ここではやめておきます。
今回は計算を理解するためにベタに偏微分を解いてみたのですが、ゴチャゴチャしてよくわからないので、行列を使った表記で少し整理します。
順伝播の行列表記
順伝播を下図の雰囲気に合わせて行列で表現したいと思います。
第1層
$${ \begin{pmatrix} 1 \\ { x }_{ 1 } \\ { x }_{ 2 } \\ { x }_{ 3 } \\ { x }_{ 4 } \end{pmatrix} }^{ T }\begin{pmatrix} { b }_{ 0,1 }^{ (1) } & { b }_{ 0,2 }^{ (1) } & { b }_{ 0,3 }^{ (1) } \\ { w }_{ 1,1 }^{ (1) } & { w }_{ 1,2 }^{ (1) } & { w }_{ 1,3 }^{ (1) } \\ { w }_{ 2,1 }^{ (1) } & { w }_{ 2,2 }^{ (1) } & { w }_{ 2,3 }^{ (1) } \\ { w }_{ 3,1 }^{ (1) } & { w }_{ 3,2 }^{ (1) } & { w }_{ 3,3 }^{ (1) } \\ { w }_{ 4,1 }^{ (1) } & { w }_{ 4,2 }^{ (1) } & { w }_{ 4,3 }^{ (1) } \end{pmatrix}=\begin{pmatrix} { a }_{ 1 }^{ (1) } \\ { a }_{ 2 }^{ (1) } \\ { a }_{ 3 }^{ (1) } \end{pmatrix}^{ T }\quad \rightarrow \quad \begin{pmatrix} { f }^{ (1) }\left( { a }_{ 1 }^{ (1) } \right) \\ { f }^{ (1) }\left( { a }_{ 2 }^{ (1) } \right) \\ { f }^{ (1) }\left( { a }_{ 3 }^{ (1) } \right) \end{pmatrix}^{ T }$$
第2層
$${ \begin{pmatrix} 1 \\ { f }^{ (1) }\left( { a }_{ 1 }^{ (1) } \right) \\ { f }^{ (1) }\left( { a }_{ 2 }^{ (1) } \right) \\ { f }^{ (1) }\left( { a }_{ 2 }^{ (1) } \right) \end{pmatrix} }^{ T }\begin{pmatrix} { b }_{ 0,1 }^{ (2) } & { b }_{ 0,2 }^{ (2) } \\ { w }_{ 1,1 }^{ (2) } & { w }_{ 1,2 }^{ (2) } \\ { w }_{ 2,1 }^{ (2) } & { w }_{ 2,2 }^{ (2) } \\ { w }_{ 3,1 }^{ (2) } & { w }_{ 3,2 }^{ (2) } \end{pmatrix}=\begin{pmatrix} { a }_{ 1 }^{ (2) } \\ { a }_{ 2 }^{ (2) } \end{pmatrix}^{ T }\quad \rightarrow \quad \begin{pmatrix} { f }^{ (2) }\left( { a }_{ 1 }^{ (2) } \right) \\ { f }^{ (2) }\left( { a }_{ 2 }^{ (2) } \right) \end{pmatrix}^{ T }$$
第3層
$${ \begin{pmatrix} 1 \\ { f }^{ (2) }\left( { a }_{ 1 }^{ (2) } \right) \\ { f }^{ (2) }\left( { a }_{ 2 }^{ (2) } \right) \end{pmatrix} }^{ T }\begin{pmatrix} { b }_{ 0,1 }^{ (3) } & { b }_{ 0,2 }^{ (3) } \\ { w }_{ 1,1 }^{ (3) } & { w }_{ 1,2 }^{ (3) } \\ { w }_{ 2,1 }^{ (3) } & { w }_{ 2,2 }^{ (3) } \end{pmatrix}=\begin{pmatrix} { a }_{ 1 }^{ (3) } \\ { a }_{ 2 }^{ (3) } \end{pmatrix}^{ T }\quad \rightarrow \quad \begin{pmatrix} { f }^{ (3) }\left( { a }_{ 1 }^{ (3) } \right) \\ { f }^{ (3) }\left( { a }_{ 2 }^{ (3) } \right) \end{pmatrix}^{ T }$$
()T は転置行列で、行と列を入れ替えます。
転置行列を使っていますが、図の感じと合わせるだけなので、覚えやすいでしょうか??
逆伝播の行列表記

行列で逆伝播を書くと最初の誤差\(\begin{pmatrix} { y }_{ 1 }-{ t }_{ 1 } \\ { y }_{ 2 }-{ t }_{ 2 } \end{pmatrix}\)が層が一つ戻るたびに重みと活性化関数の微分の値が付加され逆へと伝播されていく、最初の言ったバック感が感じられると思います。
逆伝播(学習)の実行
逆伝播は最後の層(今回の例では第3層)側から計算を行います。
以下で3層の例で説明します。
まず、第3層目の未知数に関する変数(重みとバイアス)の偏微分の値をそれぞれ求めます。
偏微分の値を求めたら、偏微分の値に学習率を掛けて、元の変数から引き、変数を更新します。
$$w\leftarrow w-\eta \frac { \partial E }{ \partial w } $$
$$b\leftarrow b-\eta \frac { \partial E }{ \partial b } $$
さらに第2層、第1層へと偏微分の値を計算し、重みとバイアスを更新します。
次に更新された重みとバイアスを用いて順伝播を行い出力値(y)を求めます。
この時点で通常は、前回の出力値よりも誤差が少ない状態(出力値が目標値に近い)となります。
再度、逆伝播を行い重みとバイアスを更新します。
この逆伝播→重みとバイアスの更新→順伝播→逆伝播→重みとバイアスの更新→・・・と繰り返し行い出力値と目標値の誤差が小さくなるように繰り返し処理を行います。
学習率の値については使用するニューラルネットワークなどにも依存ため、どの値が良いか?とは言い切れませんが、私の少ない経験的には0.01ぐらいから初めて、誤差を見ながら調整するようにします。
学習率の値が大きいと、逆伝播を繰り返す行うと、誤差の値が大きくなってしまいます。
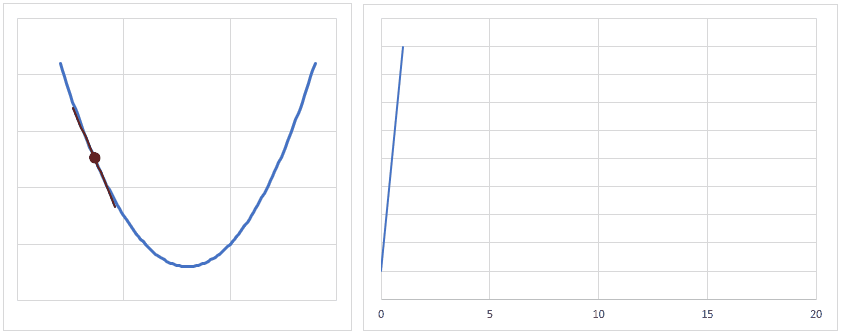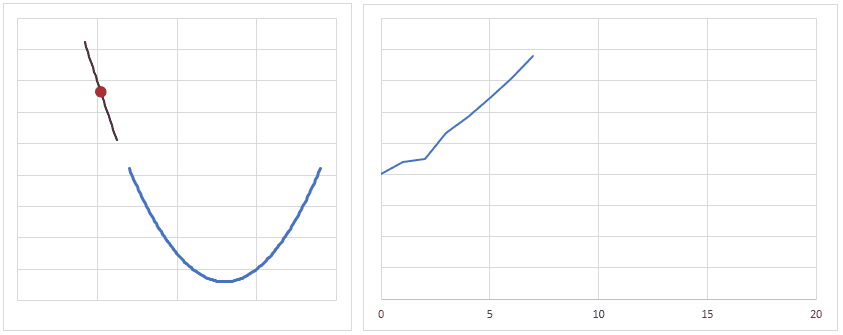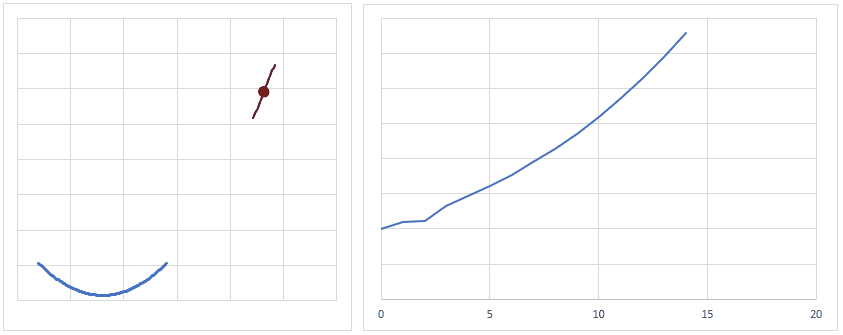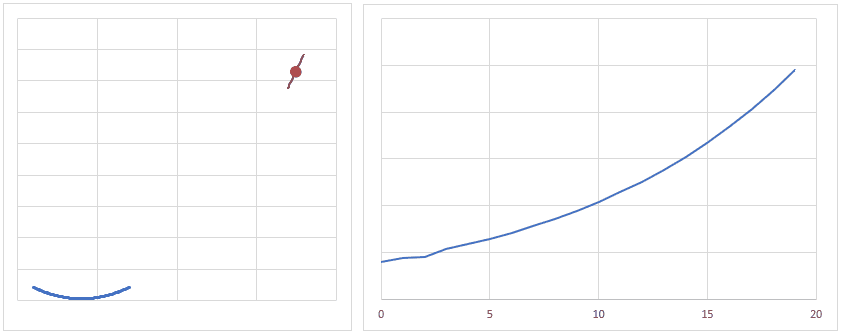
逆に学習率が小さすぎると、逆伝播を繰り返しても誤差はなかなか小さくなないため、程よく学習率を調整する必要があります。
かといって、学習率を調整して、少ない回数で誤差が小さくなるようにしすぎると、入力データによっては誤差が大きくなってしまう場合もあるので、程よく学習率を調整する必要があります。
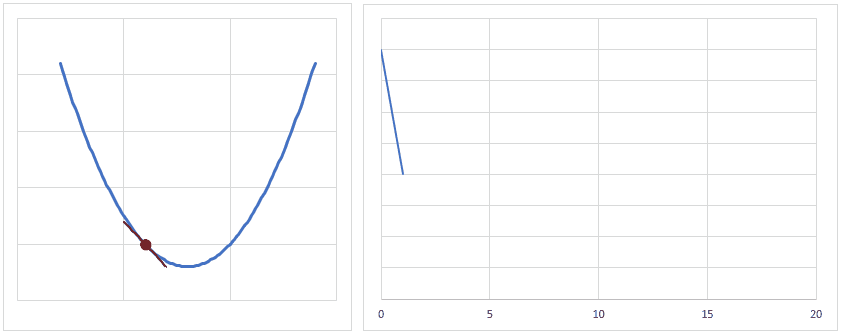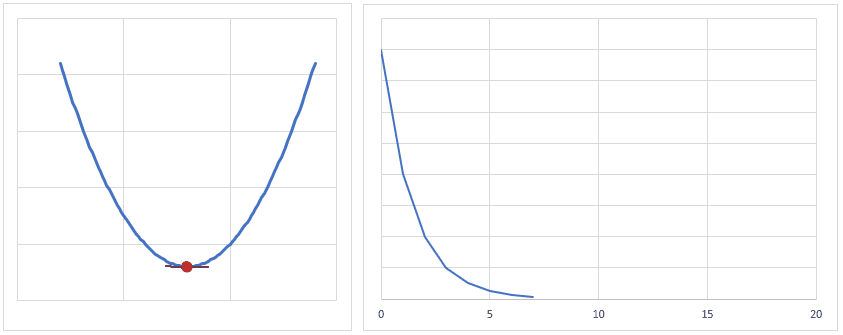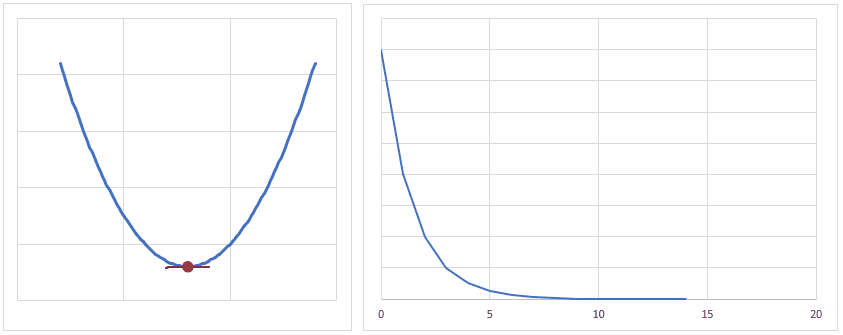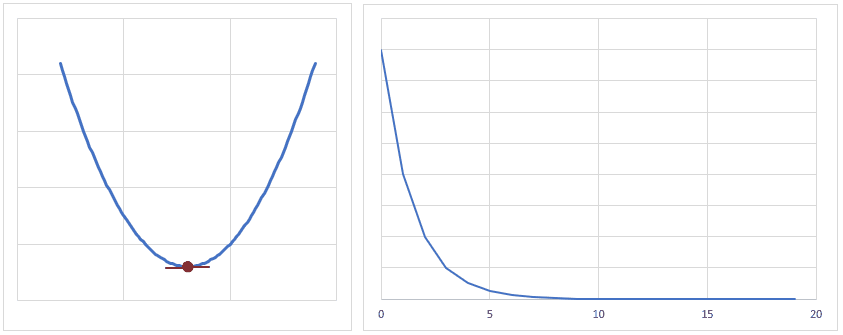
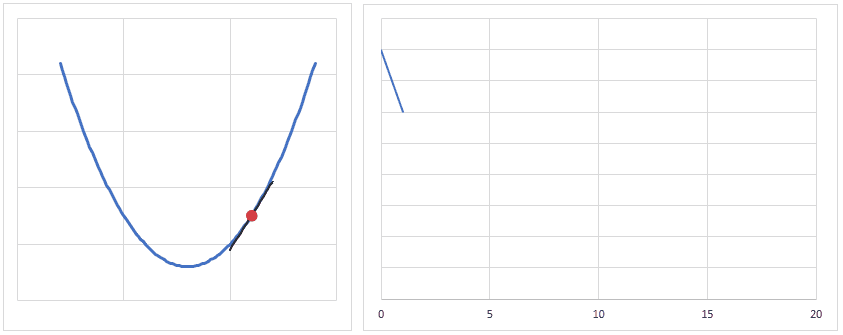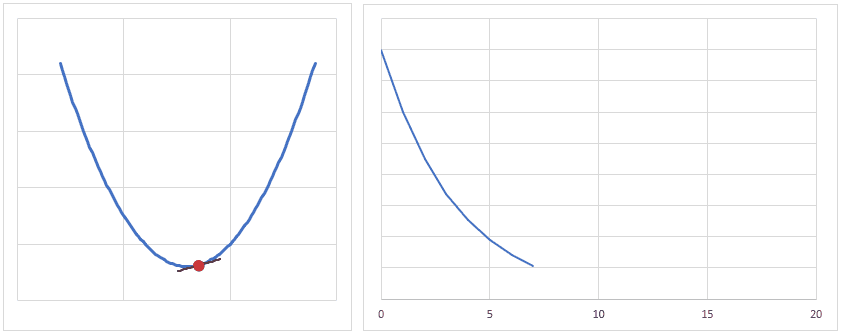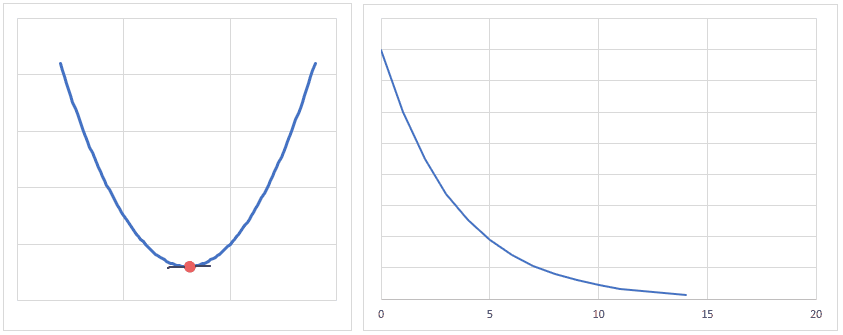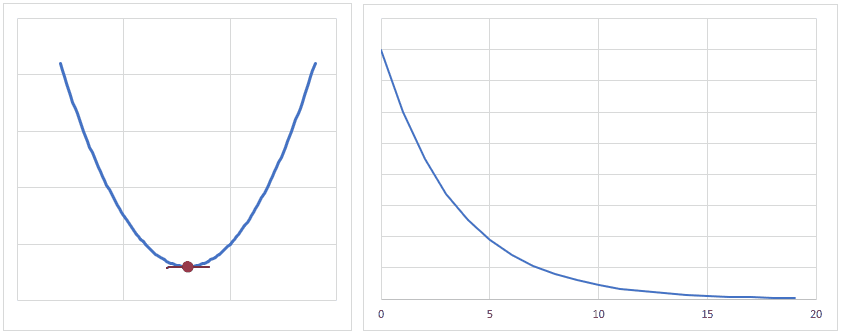
だいたいのイメージですが、下図のようになだらかに誤差が小さくなるぐらいの学習率が良いかと思います。
補足説明
行列の演算で使用した記号の補足です。
アダマール積
行列の要素同士を掛け合わせます。
$$\begin{pmatrix} a & b \\ c & d \end{pmatrix}\circ \begin{pmatrix} e & f \\ g & h \end{pmatrix}=\begin{pmatrix} ae & bf \\ cg & dh \end{pmatrix}$$
転置行列
行列の行と列を入れ替えます。
$${ \begin{pmatrix} a & b \\ c & d \\ e & f \end{pmatrix} }^{ T }=\begin{pmatrix} a & c & e \\ b & d & f \end{pmatrix}$$
シグモイド関数
$$f\left( x \right) =\frac { 1 }{ 1+{ e }^{ -x } } $$
シグモイド関数の微分
$$f’\left( x \right) =(1-f\left( x \right) )f\left( x \right) $$
コメント
[…] バックプロパゲーション(誤差逆伝搬法)をイチから理解する […]
第1層の順伝播のa2とa3の式の最初のxの添え字が2(x2)になってますが、x1ではないでしょうか。
平澤さん、ご指摘頂きありがとうございました。
確かに誤記でした。
本文も修正しました。