
PyTorchのドキュメントを毎回探してしまっているので、よく見るリンク集です。

ここでは、ある程度Deep Learningの概要やPythonについて勉強し、実際にPyTorchを使ってプログラムを組みたい人向けを想定しています。(ほぼ自分用、備忘録です)
MNISTの0~9の手書き文字画像の分類は、DeepLearningにおけるHellow World的な存在ですが、DeepLearningの画像データや正解ラベルも簡単に入手できるので、最初にプログラムを行うのには、とても便利です。
DeepLearningのプログラムを1つ作っておけば、他に流用できる部分も多いので、まずは、このMNISTをやってみたいと思います。
ここでは、Deep Learning処理の概念的な理解を重視して、ニューラルネットワーク部分はシンプルにしました。
まずは、いきなりMNISTの0~9の手書き文字画像分類のサンプルプログラムです。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
#----------------------------------------------------------
# ハイパーパラメータなどの設定値
num_epochs = 10 # 学習を繰り返す回数
num_batch = 100 # 一度に処理する画像の枚数
learning_rate = 0.001 # 学習率
image_size = 28*28 # 画像の画素数(幅x高さ)
# GPU(CUDA)が使えるかどうか?
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#----------------------------------------------------------
# 学習用/評価用のデータセットの作成
# 変換方法の指定
transform = transforms.Compose([
transforms.ToTensor()
])
# MNISTデータの取得
# https://pytorch.org/vision/stable/generated/torchvision.datasets.MNIST.html#torchvision.datasets.MNIST
# 学習用
train_dataset = datasets.MNIST(
'./data', # データの保存先
train = True, # 学習用データを取得する
download = True, # データが無い時にダウンロードする
transform = transform # テンソルへの変換など
)
# 評価用
test_dataset = datasets.MNIST(
'./data',
train = False,
transform = transform
)
# データローダー
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size = num_batch,
shuffle = True)
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size = num_batch,
shuffle = True)
#----------------------------------------------------------
# ニューラルネットワークモデルの定義
class Net(nn.Module):
def __init__(self, input_size, output_size):
super(Net, self).__init__()
# 各クラスのインスタンス(入出力サイズなどの設定)
self.fc1 = nn.Linear(input_size, 100)
self.fc2 = nn.Linear(100, output_size)
def forward(self, x):
# 順伝播の設定(インスタンスしたクラスの特殊メソッド(__call__)を実行)
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#----------------------------------------------------------
# ニューラルネットワークの生成
model = Net(image_size, 10).to(device)
#----------------------------------------------------------
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
#----------------------------------------------------------
# 最適化手法の設定
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate)
#----------------------------------------------------------
# 学習
model.train() # モデルを訓練モードにする
for epoch in range(num_epochs): # 学習を繰り返し行う
loss_sum = 0
for inputs, labels in train_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# optimizerを初期化
optimizer.zero_grad()
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss = criterion(outputs, labels)
loss_sum += loss
# 勾配の計算
loss.backward()
# 重みの更新
optimizer.step()
# 学習状況の表示
print(f"Epoch: {epoch+1}/{num_epochs}, Loss: {loss_sum.item() / len(train_dataloader)}")
# モデルの重みの保存
torch.save(model.state_dict(), 'model_weights.pth')
#----------------------------------------------------------
# 評価
model.eval() # モデルを評価モードにする
loss_sum = 0
correct = 0
with torch.no_grad():
for inputs, labels in test_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss_sum += criterion(outputs, labels)
# 正解の値を取得
pred = outputs.argmax(1)
# 正解数をカウント
correct += pred.eq(labels.view_as(pred)).sum().item()
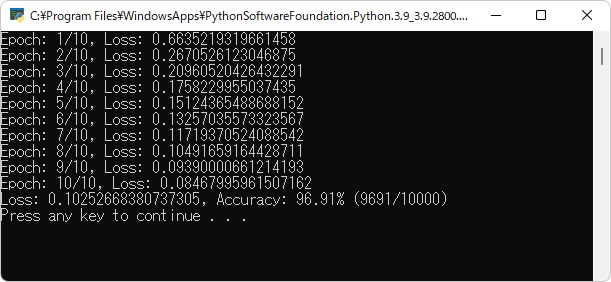
print(f"Loss: {loss_sum.item() / len(test_dataloader)}, Accuracy: {100*correct/len(test_dataset)}% ({correct}/{len(test_dataset)})")
実行結果
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transformstorchは、もちろんPyTorch用のモジュールです。
torchvisionはPyTorchの画像を使ったDeepLearning処理のための補助モジュールで、データセットの作成や、画像データからテンソルへの変換、画像の水増しなどを行います。
#----------------------------------------------------------
# ハイパーパラメータなどの設定値
num_epochs = 10 # 学習を繰り返す回数
num_batch = 100 # 一度に処理する画像の枚数
learning_rate = 0.001 # 学習率
image_size = 28*28 # 画像の画素数(幅x高さ)
# GPU(CUDA)が使えるかどうか?
device = 'cuda' if torch.cuda.is_available() else 'cpu'エポック数(繰り返し回数)、学習率など、設定を変更するパラメータは、一か所にまとめておくと変更しやすいので便利です。
#----------------------------------------------------------
# 学習用/評価用のデータセットの作成
# 変換方法の指定
transform = transforms.Compose([
transforms.ToTensor()
])
# MNISTデータの取得
# https://pytorch.org/vision/stable/generated/torchvision.datasets.MNIST.html#torchvision.datasets.MNIST
# 学習用
train_dataset = datasets.MNIST(
'./data', # データの保存先
train = True, # 学習用データを取得する
download = True, # データが無い時にダウンロードする
transform = transform # テンソルへの変換など
)
# 評価用
test_dataset = datasets.MNIST(
'./data',
train = False,
transform = transform
)
# データローダー
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size = num_batch,
shuffle = True)
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size = num_batch,
shuffle = True)データセットとは、推論を行うためのデータとラベル(正解データ)のセットの集まりです。
学習時に用いる画像と評価時に用いる画像を別の画像にするため、学習用のデータセットは train = True
評価用のデータセットは train = False に設定します。
データローダーは、学習時にデータセットの中からbatch_size個分だけ、まとめてデータを取り出します。
後述する学習時のfor分の部分で、以下のように書いている部分が、データローダーの中からデータとラベルをbatch_size個ずつ取り出している部分となります。
for inputs, labels in train_dataloader:
: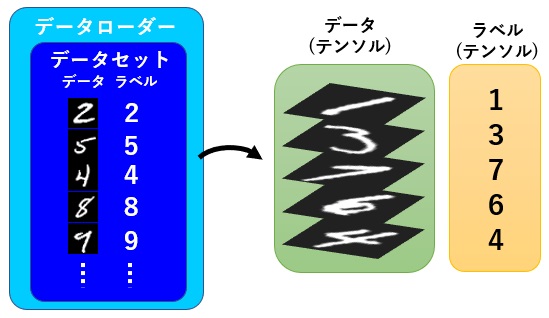
このデータを取り出す際に、データを拡大、縮小、移動などを行い、見かけ上のデータ数を増やす水増しと言われる処理や、データを並び替えて値を0~1の値に収まるように変換し、テンソルと呼ばれるデータ形式に変更します。
”テンソル”という言葉が出てくると、いきなり難しくも感じるのですが、プログラム的に言うと、ただの多次元配列となります。
画像データの場合、幅(W)、高さ(H)、色(C)と置くと、モノクロ画像の場合[H、W]の2次元配列となり、カラーの場合は[H, W, C]の3次元配列となりますが、これにバッチ数のNを追加し、
[N, C, H, W]の順番の4次元配列に格納されたデータがテンソルとなります。
今回は、手書き文字のデータセットを用いましたが、他にも既存のデータセットがいろいろあるので、こちらを参照ください。
https://pytorch.org/vision/stable/datasets.html
また、既存のデータセットではなく、自作のデータセットを作成することも可能ですが、これについては、別途記事にしたいと思います。
#----------------------------------------------------------
# ニューラルネットワークモデルの定義
class Net(nn.Module):
def __init__(self, input_size, output_size):
super(Net, self).__init__()
# 各クラスのインスタンス(入出力サイズなどの設定)
self.fc1 = nn.Linear(input_size, 100)
self.fc2 = nn.Linear(100, output_size)
def forward(self, x):
# 順伝播の設定(インスタンスしたクラスの特殊メソッド(__call__)を実行)
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#----------------------------------------------------------
# ニューラルネットワークの生成
model = Net(image_size, 10).to(device)今回は入力に画像データ全画素数(28×28)の784個入力で、全結合(出力100個)→シグモイド→全結合(出力10個)→ログソフトマックス というとてもシンプルな物にしました。
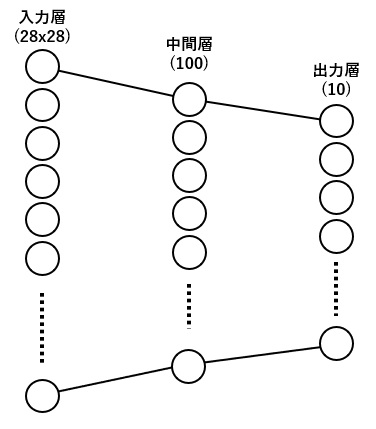
ニューラルネットワークを作成するには、nn.Moduleクラスを継承し、ニューラルネットワークのクラスを作成します。ここではクラス名を Net としましたが、クラス名についての制限はありません。
通常、作成するクラスのコンストラクタ(__init__)の部分で、各層で使われる処理(ここでは全結合のLinear)のクラスのインスタンスにより、入力サイズや出力サイズ、各種オプション設定を行います。
順伝播される処理の流れは forwardメソッド(メソッド名はforwardであること)により定義します。
例えば
x = self.fc1(x)の部分では、コンストラクタの部分で定義したLinearクラスのインスタンス(self.fc1)にカッコ() を付けて、入力データである x を引数のように渡していますが、この書き方はPython特有で、実際には Linearクラスの
__call__メソッドが呼ばれます。
このような書き方を特殊メソッドというのですが、詳細は下記ページを参照ください。
(参考)
#----------------------------------------------------------
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
#----------------------------------------------------------
# 学習中にて
# 損失(出力とラベルとの誤差)の計算
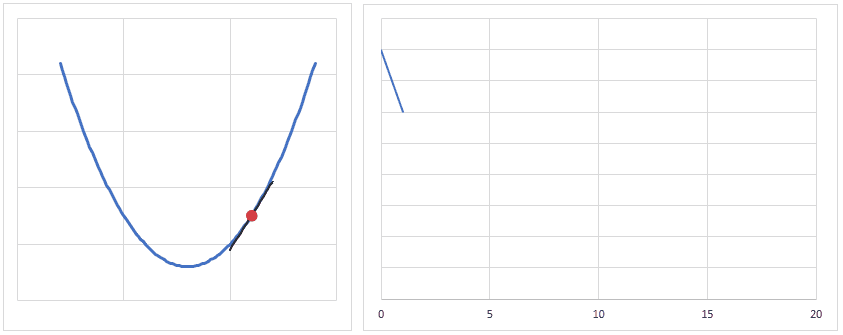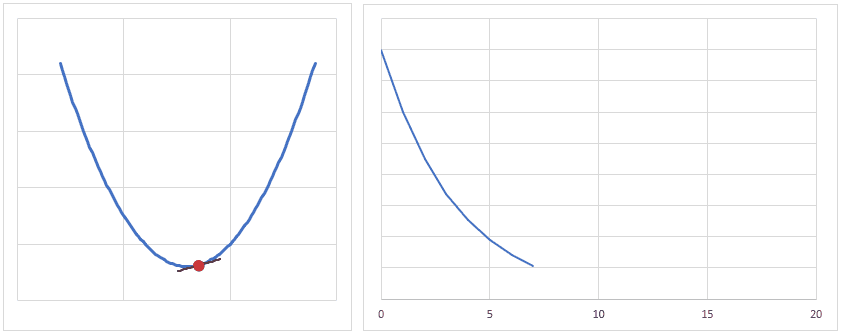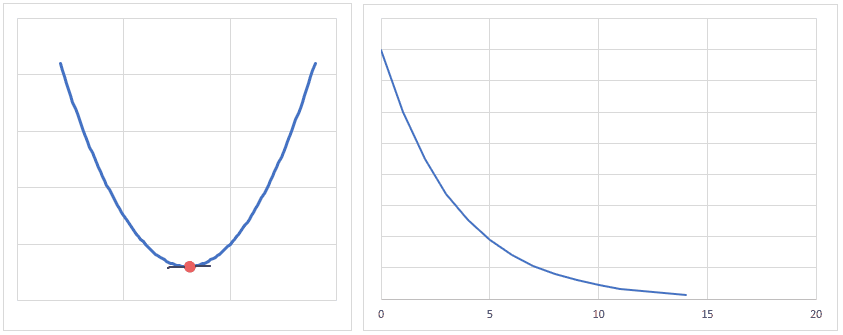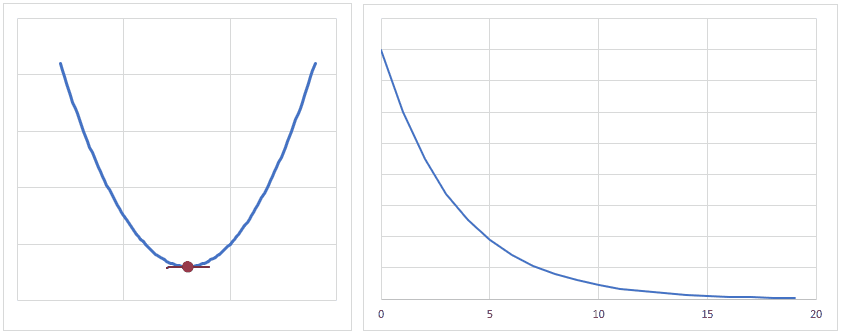
loss = criterion(outputs, labels)損失関数は、ニューラルネットワークの出力と、ラベルとの誤差を計算します。
今回、損失関数に用いているCrossEntropyLossは損失関数の中では少し特殊で、複数の出力の値とラベル1つの値との誤差を計算しています。
よくあるのは、出力の数とラベルの数は同じ数で、下図のようなイメージとなります。
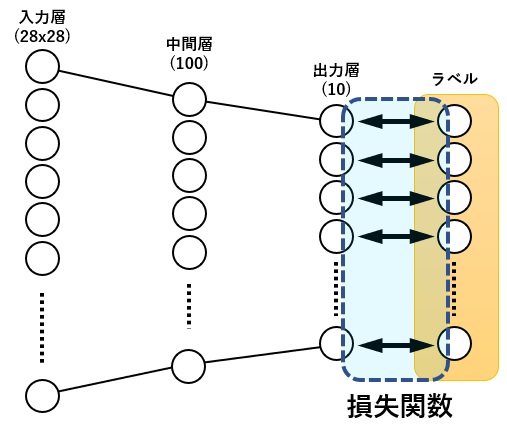
学習の工程では、この誤差が小さくなるよう、各層の重みの調整を繰り返し行います。
(参考)
https://pytorch.org/docs/stable/nn.html#loss-functions
#----------------------------------------------------------
# 最適化手法の設定
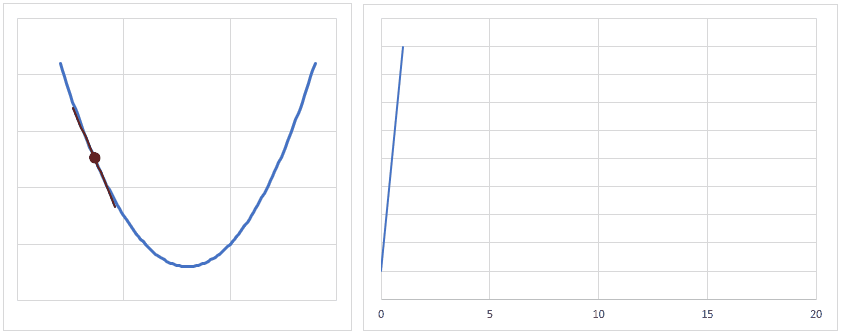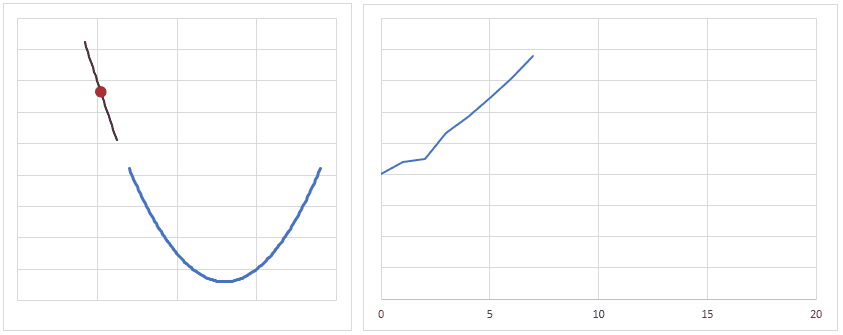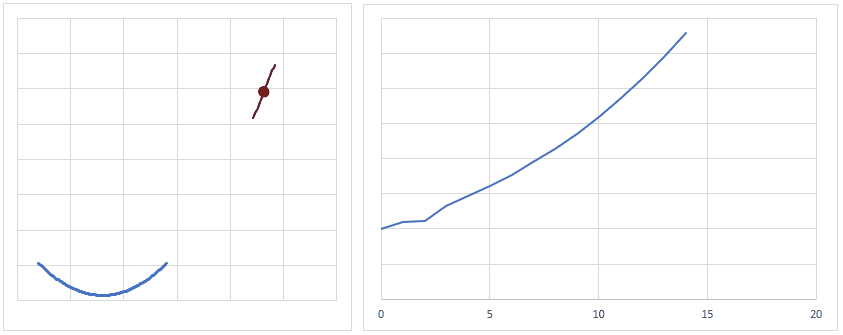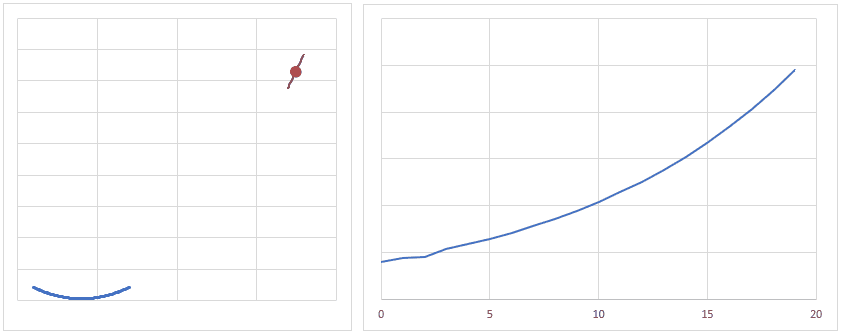
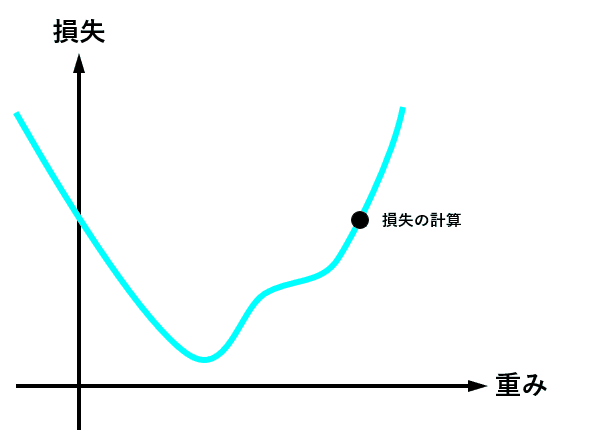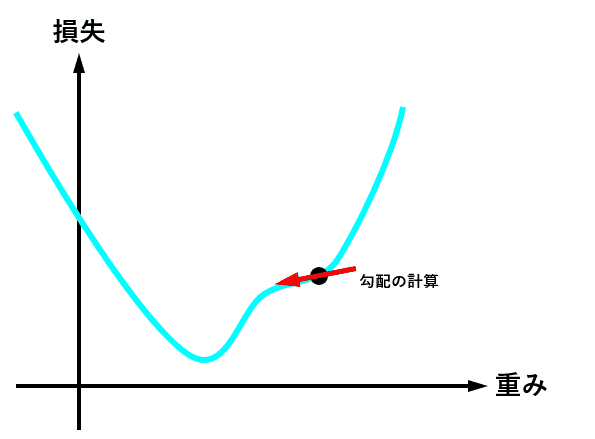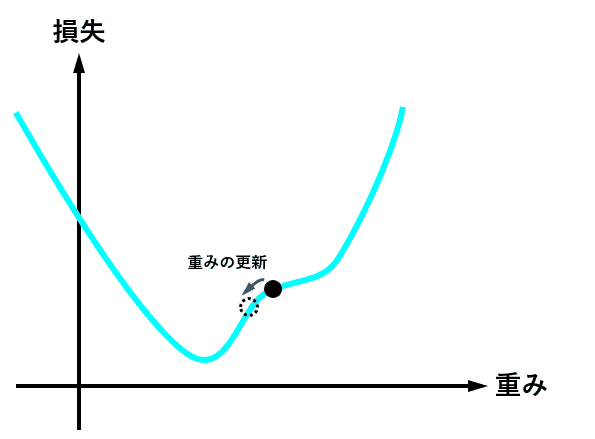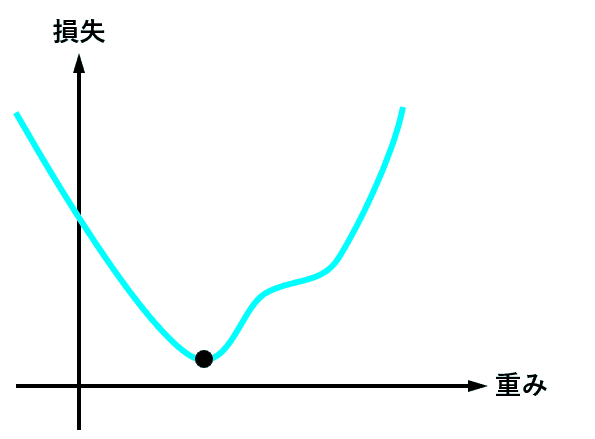
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate) 最適化関数は、損失関数から求めた勾配(損失関数を求める重みで偏微分し、現時点の重みを代入した値)を元に、最適値へ近づけるための手法です。
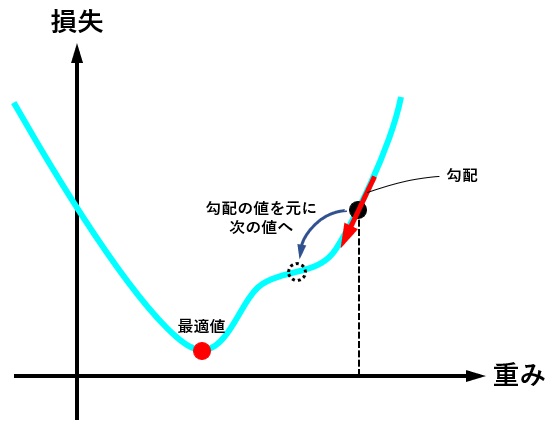
下図は、重みの値が最適値に更新されるときのイメージですが、現時点の重みが最適値から離れている場合は勾配(接線の傾き)は大きくなり、より大きく最適値に近づくように重みの値が更新されます。
逆に、重みの値が最適値に近づくと、勾配が小さくなり、重みの更新量も少なくなります。
学習率(lr)は、値が大きいと早く最適値へ近づくようになりますが、大きすぎると逆に最適値から離れてしまうので、注意が必要です。
とりあえずは lr = 0.001 ぐらいから始めてみるといいかも?しれません。
(参考)
https://pytorch.org/docs/stable/optim.html
#----------------------------------------------------------
# 学習
model.train() # モデルを訓練モードにする
for epoch in range(num_epochs): # 学習を繰り返し行う
loss_sum = 0
for inputs, labels in train_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# optimizerを初期化
optimizer.zero_grad()
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss = criterion(outputs, labels)
loss_sum += loss
# 勾配の計算
loss.backward()
# 重みの更新
optimizer.step()
# 学習状況の表示
print(f"Epoch: {epoch+1}/{num_epochs}, Loss: {loss_sum.item() / len(train_dataloader)}")
# モデルの重みの保存
torch.save(model.state_dict(), 'model_weights.pth')学習の工程は、各重みを最適値へ近づけるため、for分で繰り返し処理を行うのですが、学習の部分で重要な部分を抜き出すと
# optimizerを初期化
optimizer.zero_grad()
# 損失(出力とラベルとの誤差)の計算
loss = criterion(outputs, labels)
# 勾配の計算
loss.backward()
# 重みの更新
optimizer.step()の繰り返しとなっています。
この繰り返しのイメージは、こんな感じ↓です。
#----------------------------------------------------------
# 評価
model.eval() # モデルを評価モードにする
loss_sum = 0
correct = 0
with torch.no_grad():
for inputs, labels in test_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss_sum += criterion(outputs, labels)
# 正解の値を取得
pred = outputs.argmax(1)
# 正解数をカウント
correct += pred.eq(labels.view_as(pred)).sum().item()
print(f"Loss: {loss_sum.item() / len(test_dataloader)}, Accuracy: {100*correct/len(test_dataset)}% ({correct}/{len(test_dataset)})")
今回は、0~9までの画像分類を行っているので、出力(output)は10個のテンソルデータとなり、この10個のデータの配列中、値が最大となる値のインデックス番号が、推測された数字の値(0~9)と一致するようになっています。
ここで紹介しているサンプルは、Deep Learningをするはしめの一歩として、もろもろシンプルにしています。
ニューラルネットワークはシンプルだし、学習中の過学習の評価用に検証データも欲しいし、画像も表示したい。
と、いろいろ不足しているかと思いますが、おいおい記事にしたいと思います。
PyTorchそのものは、画像を使ったDeepLearningで行われる、画像の分類、認識、領域分割専用に作られている訳では無いので、最初のハードルが少々高く感じます。
さらに、画像データをニューラルネットワークに流すには、画像データをテンソルに変換して。。
とかいうと、なぜか難しく感じてしまいます。
テンソルも、ただの配列なのに、numpyのndarrayは、比較的容易に受け入れていたのに、なぜ、PyTorchのテンソルは受け入れ難く感じるのか??
本記事では、その辺のハードルが少しでも下がって感じてもらえると幸いです。
DeepLearningのプログラムは、ほとんどがPythonで書かれる場合が多いのですが、画像入力やGUI部分をプログラムしたいとなると、やっぱりC#で組みたい!
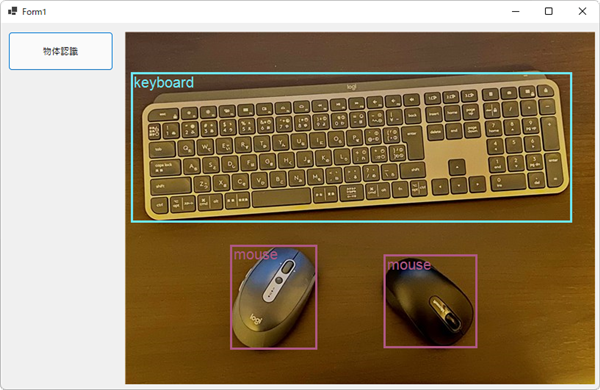
ということで、学習まではPythonで行い、学習結果をONNXに保存し、ONNXをC#から読み込んでC#で推論を行う方針で、いろいろ調べてみたのですが、分からない部分もボロボロと...
とりあえず、出来た事のメモです。
作成したプログラムのイメージ
今回は.NET Coreを使って作成していますが、.NET Frameworkでも大丈夫です。
今回は、画像認識モデル(Object Detection)をONNXファイルに保存するサンプルです。
入力画像サイズや出力の名前を使用するモデルに合わせる必要があります。
import torch
import torchvision
# 入力画像サイズ(N, C, H, W)
x = torch.randn(1, 3, 480, 640)
# 学習済みモデル
# 参考 https://pytorch.org/vision/main/models.html#object-detection-instance-segmentation-and-person-keypoint-detection
model = torchvision.models.detection.fasterrcnn_mobilenet_v3_large_320_fpn(pretrained=True)
# ONNXファイルに保存
# 参考 https://pytorch.org/docs/stable/onnx.html
torch.onnx.export(
model, # ニューラルネットワークモデル
x, # 入力データ
'fasterrcnn_mobilenet_v3_large_320_fpn.onnx', # ONNXファイル名
opset_version=11, # ONNXバージョン
input_names = ['input'], # 入力の名前
output_names = ["boxes", "labels", "scores"] # 出力の名前
)input_names と output_names の指定は省略可能です。
C#でONNXを扱えるライブラリは、いくつかあるようなのですが、今回は、マイクロソフトのOnnxRuntimeを使いました。
フォームにはボタン(button1)とピクチャボックス(pictureBox1)のみを配置しています。
使用には、NuGetでMicrosoft.ML.OnnxRuntimeを追加する必要があります。
以下は、私が分かっていない部分なので、出来るかも?しれません。
https://pytorch.org/vision/main/models.html#object-detection-instance-segmentation-and-person-keypoint-detection
https://pytorch.org/docs/stable/onnx.html
https://docs.microsoft.com/ja-jp/windows/ai/windows-ml/tutorials/pytorch-convert-model
https://docs.microsoft.com/ja-jp/windows/ai/windows-ml/get-started-uwp
https://docs.microsoft.com/ja-jp/dotnet/machine-learning/tutorials/object-detection-onnx
私はC#をメインで使っているので、Pythonのプログラムを組む時も慣れたVisual Studioで行っています。
さらに、Visual Studio 2019であればPythonの環境(バージョン)ごとにインストールするのも簡単なのですが、PyTorchをインストールするときは、少々、ハマったので、そのメモです。。
PythonモジュールのインストールはPython環境で、インストールしたい環境(バージョン)を選択し、 PyPIとインストールされたパッケージの検索 の部分に torch と入力して、Enterを押せば、インストールできるかも?知れないのですが、インストールされるPyTorchのバージョンやGPUの対応などに不安があったので、別の方法でインストールを行いました。
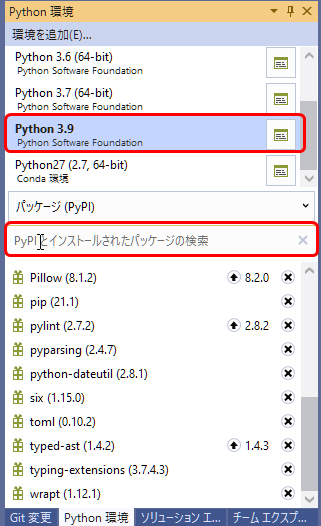
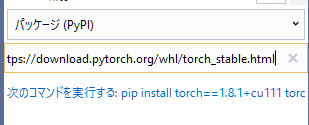
まず、PyTorchのページへ移動し、少し下に表示されているバージョンやOSの選択表示部分で、自分のインストールしたい環境を選択します。
私の場合は以下のように選択しました。
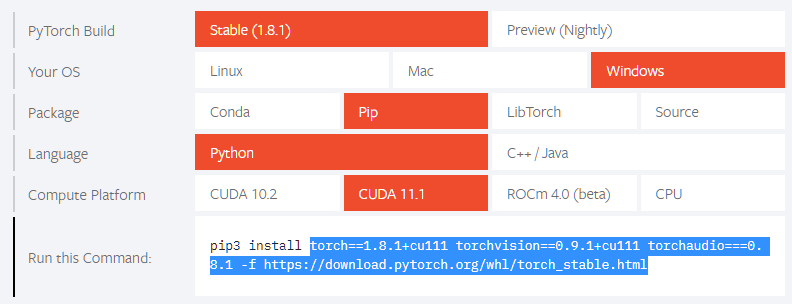
すると、Run this Commandの部分に
pip3 install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
と表示されているので、この torch以降の部分を選択し、コピー(Ctrl+C)します。
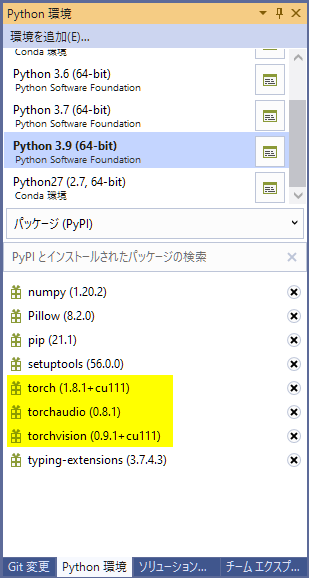
コピーしたテキストを、 PyPIとインストールされたパッケージの検索 の部分に貼り付け(Ctrl+V)ると、 次のコマンドを実行する のリンクが表示されるので、この部分をクリックすると、PyTorchのインストールが始まります。
これで、特に問題が無かった人は以下のように torch, torchaudio, torchvision の3つがインストールされると思います。
しかし、私はそう簡単にはいきませんでした。。
そもそも自分のPCにインストールされているCUDAのバージョンがわからなかったのですが、CUDAのバージョンを調べるにはコマンドプロンプトから、
nvcc -V
と入力すると、CUDAのバージョンを調べることができます。
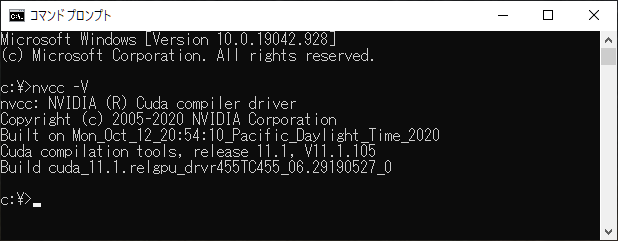
私の場合、CUDAのバージョンが古かったので、CUDAもインストールしました。
(参考)
さらに、pip install 中に、このような↓メッセージが表示されたのですが、
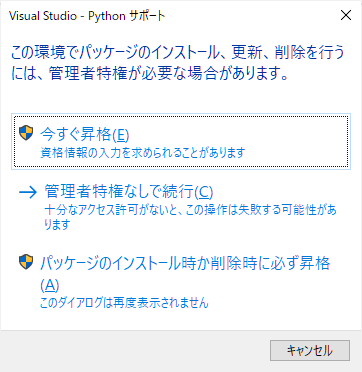
ここで今すぐ昇格をクリックして、インストールを続けても、下記のようなエラーが表示されて、インストールできませんでした。
----- 'torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html' をインストールしています -----
Looking in links: https://download.pytorch.org/whl/torch_stable.html
Collecting torch==1.8.1+cu111
Using cached https://download.pytorch.org/whl/cu111/torch-1.8.1%2Bcu111-cp39-cp39-win_amd64.whl (3055.6 MB)
Collecting torchvision==0.9.1+cu111
Using cached https://download.pytorch.org/whl/cu111/torchvision-0.9.1%2Bcu111-cp39-cp39-win_amd64.whl (1.9 MB)
Collecting torchaudio===0.8.1
Using cached torchaudio-0.8.1-cp39-none-win_amd64.whl (109 kB)
Requirement already satisfied: typing-extensions in c:\users\akira\appdata\local\packages\pythonsoftwarefoundation.python.3.9_qbz5n2kfra8p0\localcache\local-packages\python39\site-packages (from torch==1.8.1+cu111) (3.7.4.3)
Requirement already satisfied: numpy in c:\users\akira\appdata\local\packages\pythonsoftwarefoundation.python.3.9_qbz5n2kfra8p0\localcache\local-packages\python39\site-packages (from torch==1.8.1+cu111) (1.20.2)
Requirement already satisfied: pillow>=4.1.1 in c:\users\akira\appdata\local\packages\pythonsoftwarefoundation.python.3.9_qbz5n2kfra8p0\localcache\local-packages\python39\site-packages (from torchvision==0.9.1+cu111) (8.2.0)
Installing collected packages: torch, torchvision, torchaudio
ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: 'C:\\Users\\akira\\AppData\\Local\\Packages\\PythonSoftwareFoundation.Python.3.9_qbz5n2kfra8p0\\LocalCache\\local-packages\\Python39\\site-packages\\caffe2\\python\\serialized_test\\data\\operator_test\\collect_and_distribute_fpn_rpn_proposals_op_test.test_collect_and_dist.zip'
----- 'torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html' をインストールできませんでした -----このエラーの
ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory:
の部分がいまいち意味が分からず、インストール中に管理者権限のメッセージが表示されていたので、インストール先のフォルダの権限が悪いのか?と思ったのですが、フォルダの権限の変更方法も分からず。。
結局、Pythonをアンインストールして、再インストールすることで、PyTorchもインストールできました。
ちなみに、Pythonのインストールは、下記のページ
https://www.python.org/downloads/
より、Windowsの場合であれば Download Python X.X.X の部分をクリックし、ファイルをダウンロードし、ファイルをダブルクリックしてインストールします。
インストール時に Add Python 3.9 to PATH にチェックを入れ Customize installation をクリックしてインストールします。
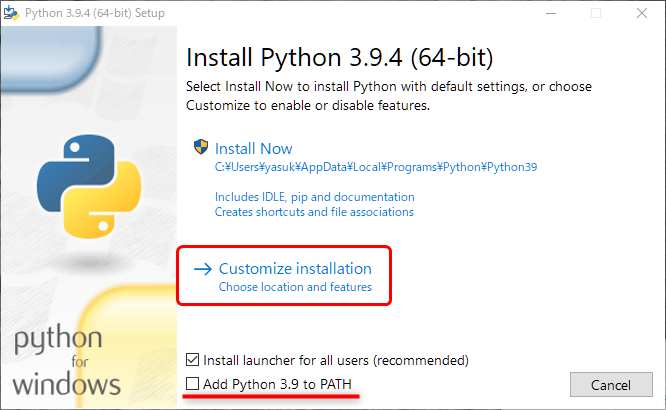
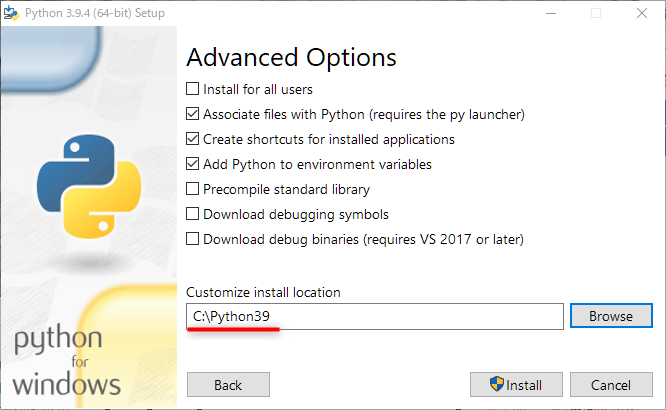
次に表示されたウィンドウでインストール先のディレクトリが指定できるので、アクセス制限のなさそうな場所を指定して、 install をクリックします。
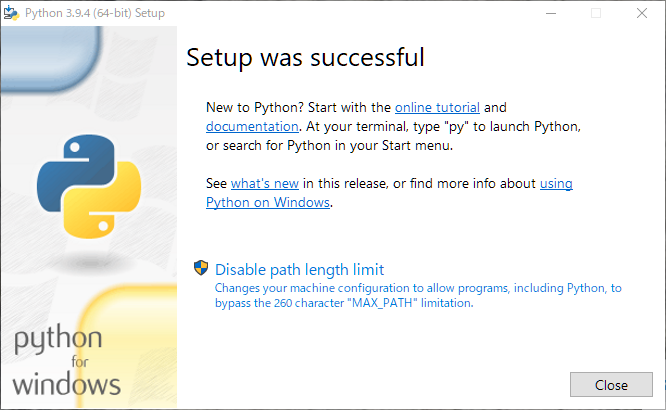
最終的に以下のようなウィンドウが表示されれば、Pythonのインストールは完了です。
ここまでやって、無事、PyTorchをインストールすることが出来ました!!
[2020.2.5]LibTorch Ver.1.4.0対応版に修正
昨年はPFNがPyTorchへ移行するというビックニュースがありましたが、それもあって、個人的に注目度の増したPyTorch
DeepLearningについては、最終的にはC#から使いたいのですが、C#に正式に対応しているのは、おそらくMicrosoftのCognitive Toolkitだけ?ですが、MicrosoftもCognitive Toolkitは今後、メンテナンスのみ行い、新しくは開発を行わないと言っているので、いつまで続くか?ちょっと不安。
C#がダメなら、ある程度C++で処理を書いて、C#から処理を呼び出す方向にしようと思い、C++に対応しているPyTorchについて調べてみました。
PyTorchのC++版はLibTorchと言うらしい。
ただし、PyTorchのC++のページ
にも、こんな文言↓が書いてあり、今後、変わる可能性も大な状況です。

Windows10
Visual Studio 2017
LibTorchバージョン 1.4.0 (2020年2月月時点の最新)
となります。
Visual Studio 2015でも試してみましたが、エラーが多発し、VS2017にしました。
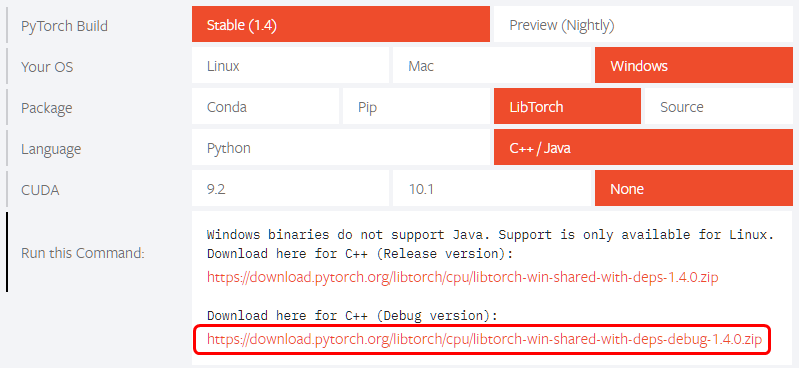
ビルド済みのLibTorchは下記、ページよりダウンロードできます。
今回は使用方法の評価をしたいので、Windows、C++版のCUDAなしのDebug版をダウンロードします。
実際に使う場合はRelease版を入手してください。
zipファイル(libtorch-win-shared-with-deps-debug-1.4.0.zip)を解凍すると、ファイル構成は以下のようになっています。
重要な部分を展開して表示しています。
└─libtorch
│ build-hash
│
├─bin
│
├─cmake
│
├─include
│ │ clog.h
│ │ cpuinfo.h
│ │ fp16.h
│ │ psimd.h
│ │
│ ├─ATen
│ ├─c10
│ ├─caffe2
│ ├─nomnigraph
│ ├─pybind11
│ ├─TH
│ ├─THCUNN
│ ├─THNN
│ └─torch
│ └─csrc
│ ├─api
│ │ ├─include
│ │ │ └─torch
│ │ │ │ all.h
│ │ │ │ arg.h
│ │ │ │ autograd.h
│ │ │ │ cuda.h
│ │ │ │ data.h
│ │ │ │ enum.h
│ │ │ │ expanding_array.h
│ │ │ │ jit.h
│ │ │ │ nn.h
│ │ │ │ optim.h
│ │ │ │ ordered_dict.h
│ │ │ │ python.h
│ │ │ │ serialize.h
│ │ │ │ torch.h
│ │ │ │ types.h
│ │ │ │ utils.h
│ │ │ │
│ │ │ ├─data
│ │ │ ├─detail
│ │ │ ├─nn
│ │ │ ├─optim
│ │ │ ├─python
│ │ │ │ init.h
│ │ │ │
│ │ │ └─serialize
│ │ │
│ │ └─src
│ ├─autograd
│ ├─cuda
│ ├─distributed
│ ├─generic
│ ├─jit
│ ├─multiprocessing
│ ├─onnx
│ ├─tensor
│ └─utils
│
├─lib
│ c10.dll
│ c10.lib
│ c10.pdb
│ caffe2_module_test_dynamic.dll
│ caffe2_module_test_dynamic.lib
│ caffe2_module_test_dynamic.pdb
│ clog.lib
│ cpuinfo.lib
│ libiomp5md.dll
│ libiompstubs5md.dll
│ libprotobuf-lited.lib
│ libprotobufd.lib
│ libprotocd.lib
│ torch.dll
│ torch.lib
│ torch.pdb
│
├─share
└─test
使用方法については、こちらのページ↓
https://mc.ai/building-pytorch-c-integration-libtorch-with-ms-visual-studio-2017/
を参考にしながら、少し手をいれました。
今回はC++のコンソールアプリケーションを作成します。
Visual Studio 2017を起動し、 新しいプロジェクトの作成 をクリックします。
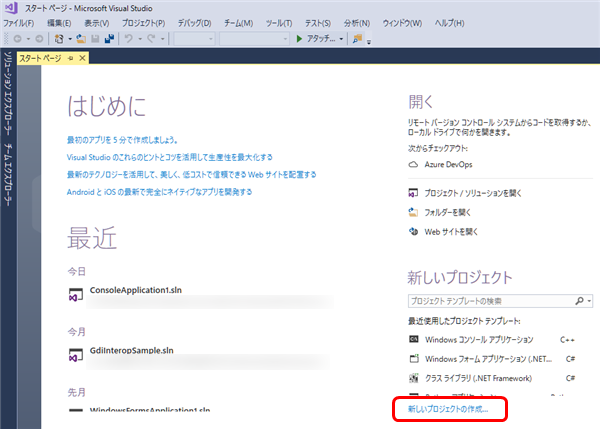
Visual C++ → Windowsデスクトップ → コンソールアプリ と選択し、名前や場所を指定して、OKボタンをクリックします。
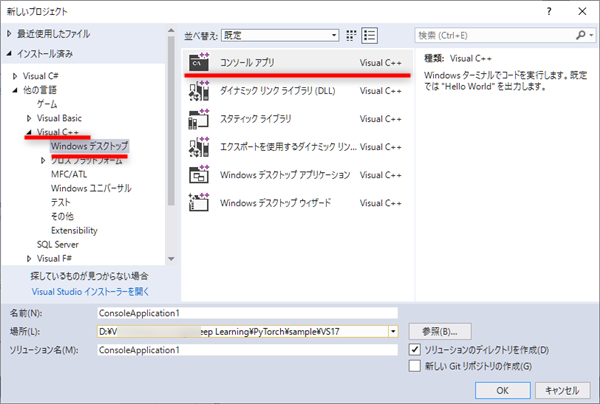
すると最小限のコンソールアプリ Hello World! が作成されます。
Visual Studioの上部のソリューションプラットフォーム部分を x64 に変更します。
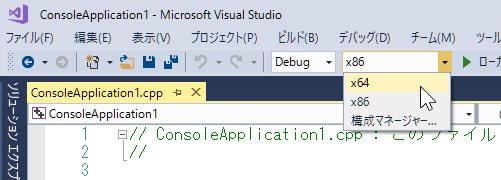
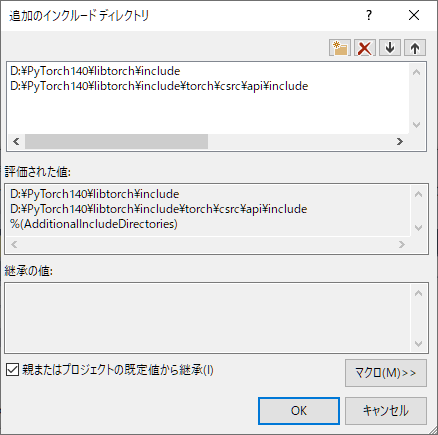
使用するヘッダファイル(*.h)の場所(ディレクトリ)を設定します。
プロジェクトのプロパティより、 C/C++ → 全般 → 追加のインクルードディレクトリ
の編集をクリックします。
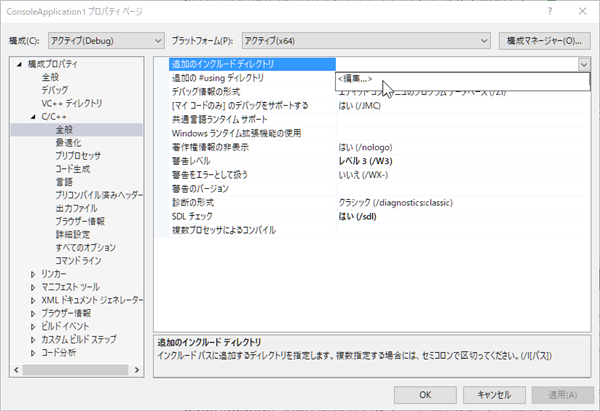
libtorch\include
libtorch\include\torch\csrc\api\include
の2つのディレクトリを指定します。
下図の D:PyTorch140の部分は各自、解凍したファイルを配置した場所に合わせて下さい。
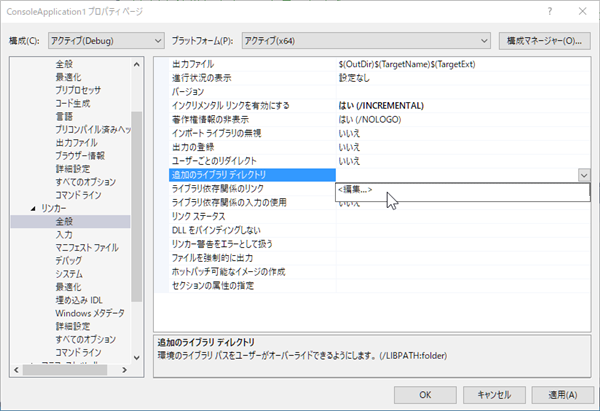
使用するライブラリファイル(*.lib)の場所(ディレクトリ)を設定します。
プロジェクトのプロパティより、 C/C++ → 全般 → 追加のライブラリディレクトリ
の編集をクリックします。
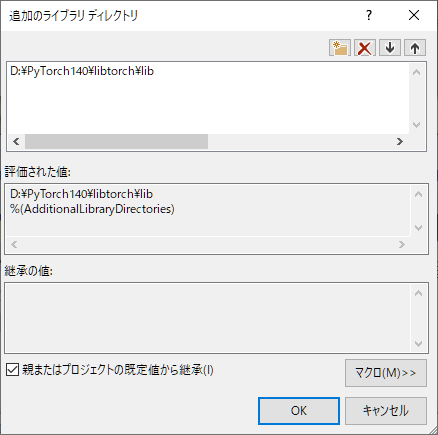
libtorch\lib
のディレクトリを指定します。
下図の D:PyTorch140の部分は各自、解凍したファイルを配置した場所に合わせて下さい。
使用するライブラリファイル(*.lib)を設定します。
プロジェクトのプロパティより、 C/C++ → 入力 → 追加の依存ファイル
の編集をクリックします。
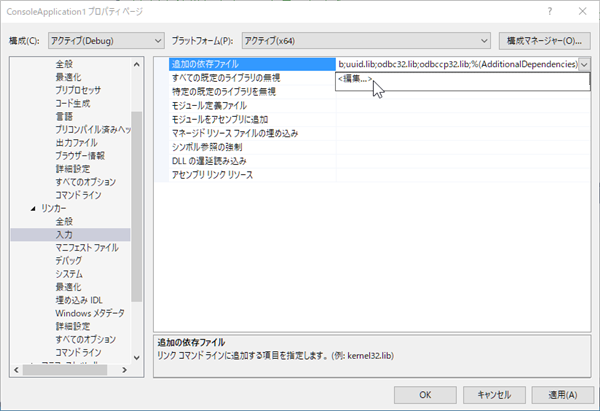
ここで、使用するライブラリファイル(*.lib)を設定するのですが、参考にしたページのファイル名が少し違っていたので、とりあえず、下記ファイルを追加しました。
c10.lib
caffe2_module_test_dynamic.lib
torch.lib
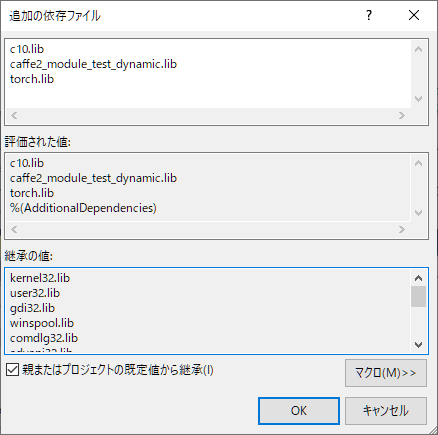
libファイルを追加したらOKボタンをクリックし、戻ったプロパティページの 適用 をクリックします。
次に、参考にしたページに従って、 C/C++ → 言語 → 準拠モード
を はい から いいえ に変更します。
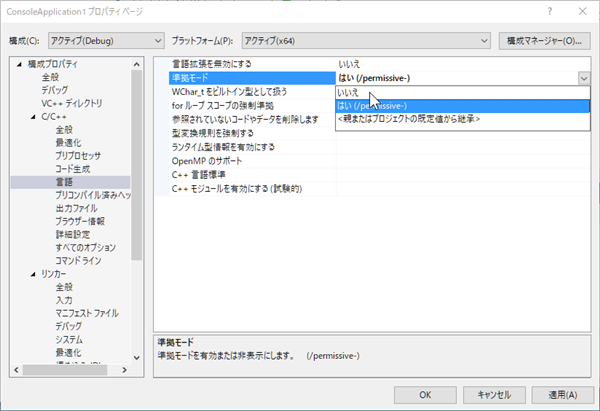
プロパティページの 適用、OK をクリックし設定画面を閉じます。
ここでも参考にしたページにしたがって、Hello World! のプログラムにiniclude
#include “torch/torch.h”
を追加してみます。

この状態でソリューションをビルドすると、エラーが1つ、警告はたくさん出てきます。
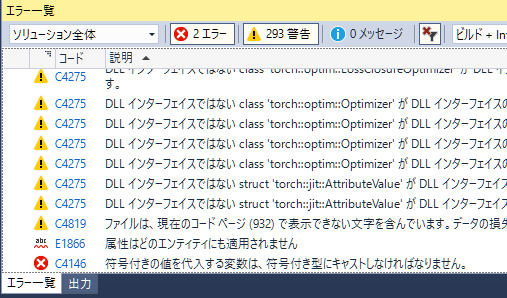
警告はあまりに多いので、エラーだけを直します。
E1866 属性はどのエンティティにも適用されませんの部分をダブルクリックすると、ArrayRef.hファイルへ飛びます。
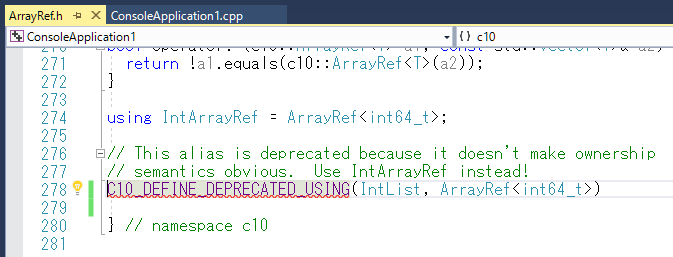
この C10_DEFINE_DEPRECATED_USING の部分が何をしているか?分からないのですが、ヒントに従って、新しいヒントファイル(cpp.hint)を追加してみたものの、修正できず。
とりあえず、コメントに Use IntArrayRef instead! と書いてあったので、コメントアウトして様子見。
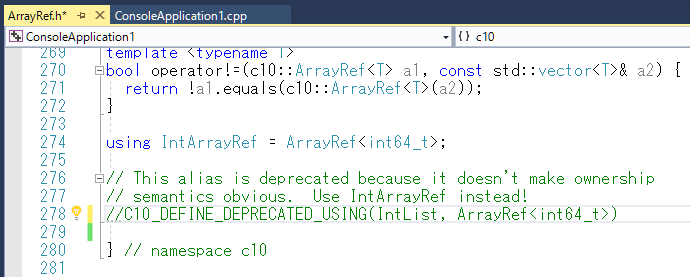
これで、エラーが出なくなりました! コメントアウトした部分が怪しいけど。。
[2020.2.24]追記
C10と付くエラーはCUDA10に関するエラーのようです。
動かすプログラムからCUDAに関連する関数を呼ぶと、C10と付くエラーが表示されるため、本ページではCUDA無しのバイナリを使用していますが、CUDA対応のバイナリを使用した方がいいかも?しれません。


























