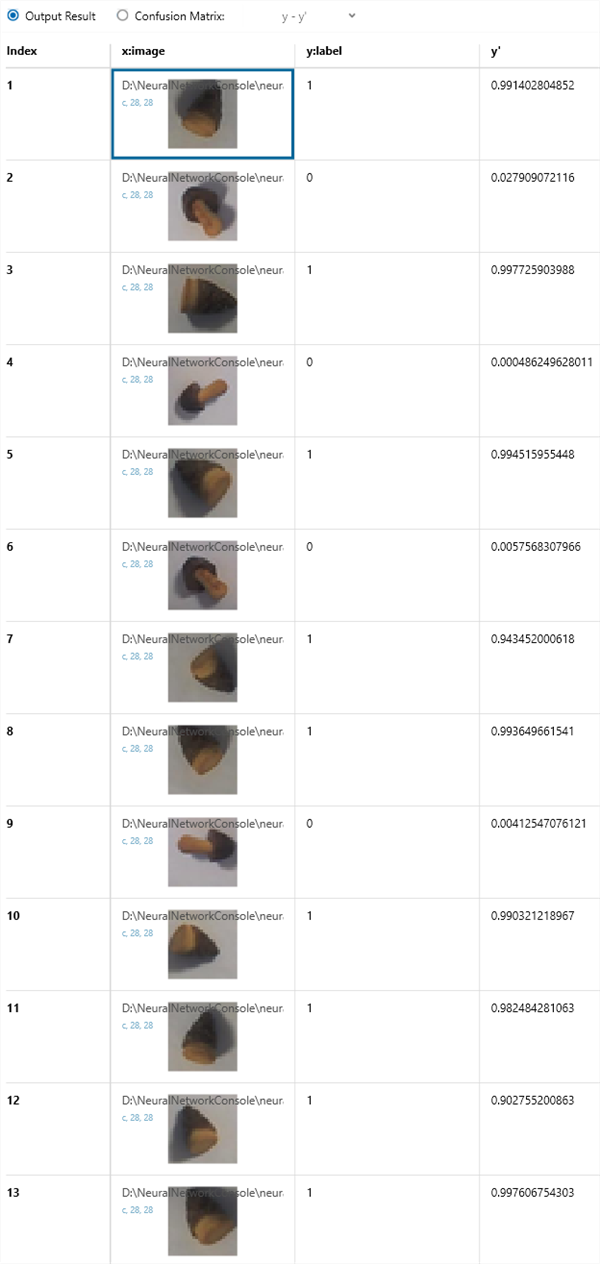
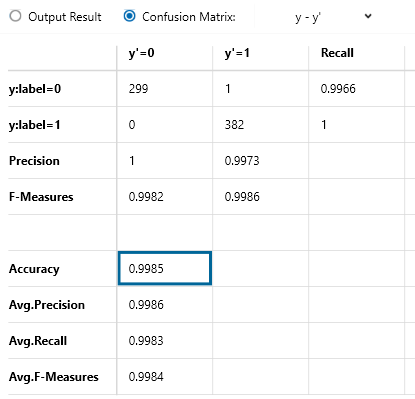
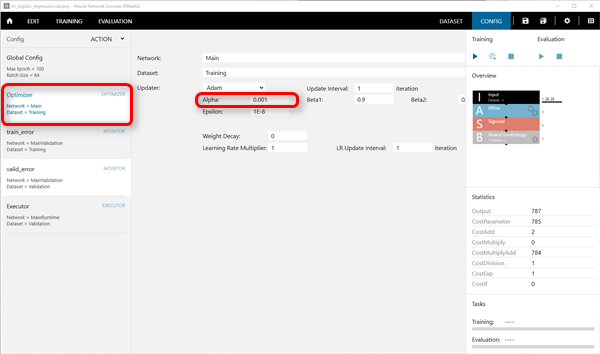
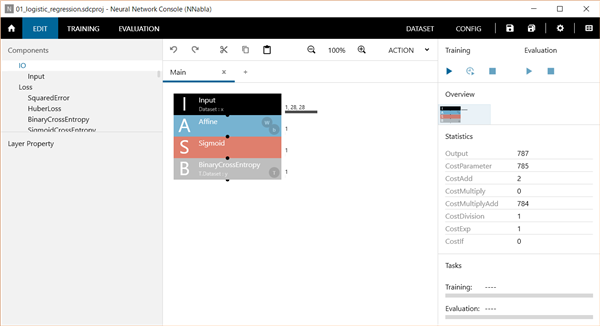
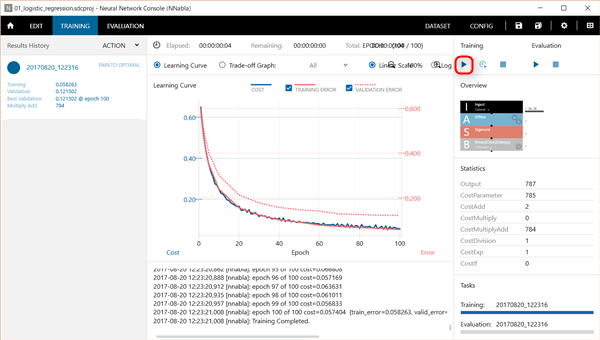
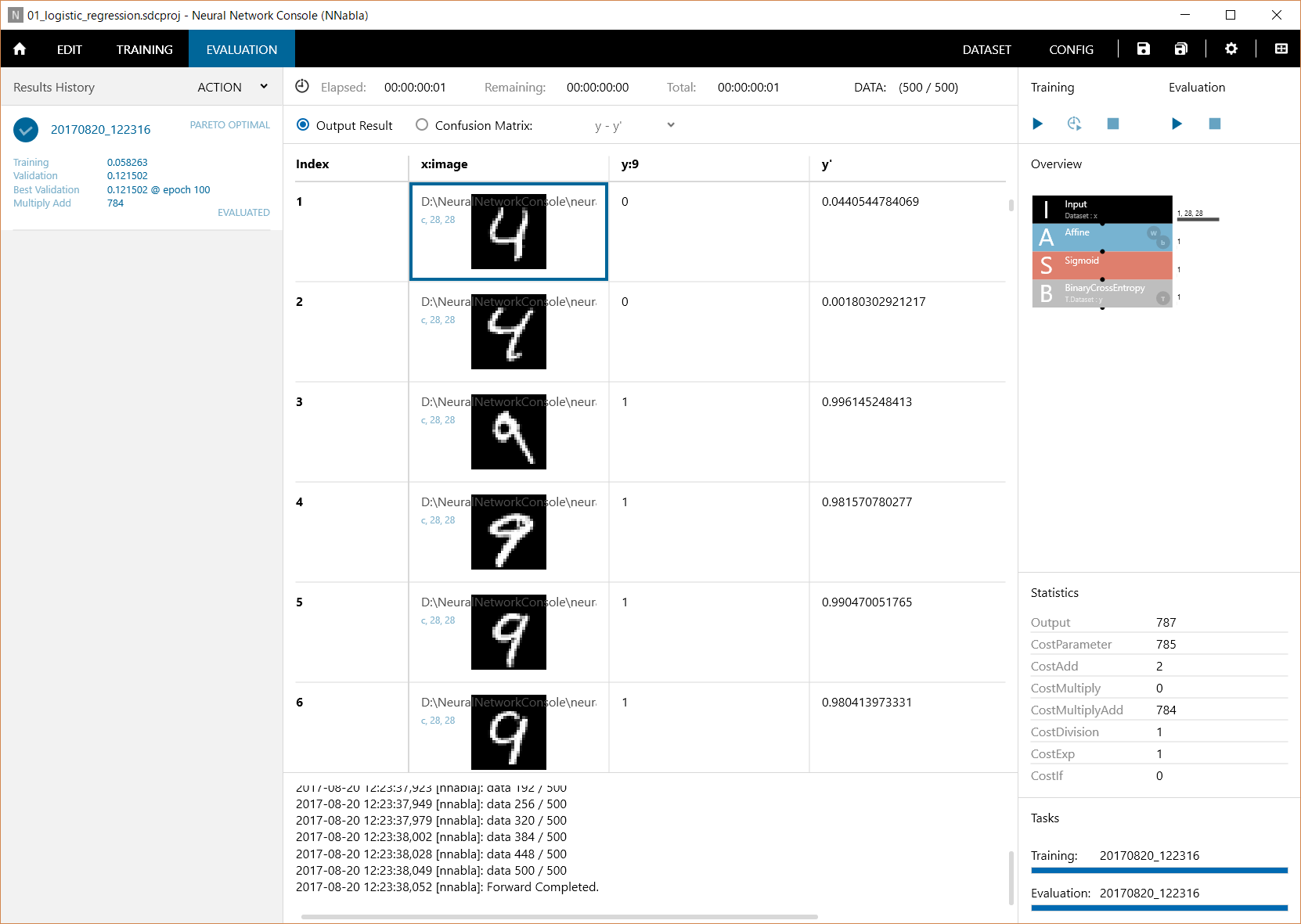
Neural Network Consoleは、触っているとすぐに結果がわかる(小さいニューラルネットワークだと。。)ので、楽しいのですが、それもだんだん飽きてきたので、処理の中身を勉強しなきゃ!と思いつつも、Neural Network Consoleで学習させたデータをNeural Network Libraryを使ってプログラムに処理を組み込む方を先に検討しようかと思っています...
まず、作成したニューラルネットワーク構造を保存するには、どこでもいいので、レイヤーの部分を右クリックします。


すると、Exportの部分があるので、Exportを選択すると、
・prototxt(Caffe用のファイル?)
・Python Code
が表示されているので、どちらかを選択します。
prototxtを選択すると、名前を付けて保存ダイアログが表示されるので、ファイルに保存すると、こんな感じ↓の内容のファイルが作成されます。
layer {
name: "Input"
type: "Data"
top: "Input"
}
layer {
name: "Convolution"
type: "Convolution"
convolution_param {
num_output: 16
kernel_size: 5
dilation: 1
}
bottom: "Input"
top: "Convolution"
}
layer {
name: "MaxPooling"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
bottom: "Convolution"
top: "MaxPooling"
}
layer {
name: "Tanh"
type: "TanH"
bottom: "MaxPooling"
top: "Tanh"
}
layer {
name: "Convolution_2"
type: "Convolution"
convolution_param {
num_output: 8
kernel_size: 5
dilation: 1
}
bottom: "Tanh"
top: "Convolution_2"
}
layer {
name: "MaxPooling_2"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
bottom: "Convolution_2"
top: "MaxPooling_2"
}
layer {
name: "Tanh_2"
type: "TanH"
bottom: "MaxPooling_2"
top: "Tanh_2"
}
layer {
name: "Affine"
type: "InnerProduct"
inner_product_param {
num_output: 10
}
bottom: "Tanh_2"
top: "Affine"
}
layer {
name: "Tanh_3"
type: "TanH"
bottom: "Affine"
top: "Tanh_3"
}
layer {
name: "Affine_2"
type: "InnerProduct"
inner_product_param {
num_output: 1
}
bottom: "Tanh_3"
top: "Affine_2"
}
layer {
name: "Sigmoid"
type: "Sigmoid"
bottom: "Affine_2"
top: "Sigmoid"
}
Python Codeを選択すると、こちらはファイルではなく、クリップボードにコピーされます。
def network(x, y, test=False):
# Input -> 1,28,28
# Convolution -> 16,24,24
with parameter_scope('Convolution'):
h = PF.convolution(x, 16, (5,5), (0,0))
# MaxPooling -> 16,12,12
h = F.max_pooling(h, (2,2), (2,2), True)
# Tanh
h = F.tanh(h)
# Convolution_2 -> 8,8,8
with parameter_scope('Convolution_2'):
h = PF.convolution(h, 8, (5,5), (0,0))
# MaxPooling_2 -> 8,4,4
h = F.max_pooling(h, (2,2), (2,2), True)
# Tanh_2
h = F.tanh(h)
# Affine -> 10
with parameter_scope('Affine'):
h = PF.affine(h, (10,))
# Tanh_3
h = F.tanh(h)
# Affine_2 -> 1
with parameter_scope('Affine_2'):
h = PF.affine(h, (1,))
# Sigmoid
h = F.sigmoid(h)
# BinaryCrossEntropy
h = F.binary_cross_entropy(h, y)
return
ただ、一番知りたかったのは、学習データそのものなのですが、こちらは学習の画面(TRAINING)の左側に表示されている学習のログの部分を右クリック→Open Result Location もしくは ダブルクリックで学習データが保存されているフォルダが表示されます。
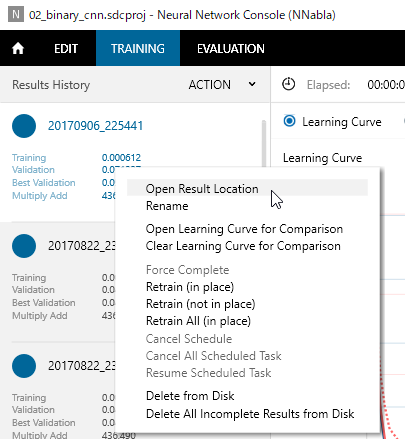

学習データの保存フォルダ↓

このフォルダには各種ログファイルと、重みやバイアスの値が格納されているファイル(*.h5)が保存されています。
この*.h5ファイルは、個人的には全く馴染みの無いファイルだったのですが、このファイルのビューアソフトは、こちらのページ↓
https://www.hdfgroup.org/downloads/hdfview/

よりダウンロードすることができます。
ただし、初めての場合はメールを登録しないとダウンロードできません。
メールを登録後、メールが来るのですが、私の場合は迷惑メールフォルダに振り分けられていたので、しばらくしてもメールが来ない場合は、迷惑メールフォルダも確認するとよいと思います。
私の場合はWindows10 64bitなので、 HDFView – Windows のファイルをダウンロードしました。
ファイル(HDFView-3.0-win7_64.zip)をダウンロード後、解凍するとセットアップファイル(HDFView-3.0.msi)があるので、このファイルをダブルクリックして実行します。
あとは表示に従って次へ次へ進めていけば、インストールができます。
最後に Launch HDFVie-3.0.0 の部分にチェックを入れ、Finishボタンをクリックすると、ビューアのプログラムが起動します。
これで、先ほどの学習データの保存フォルダに格納されているh5ファイルを開こうとしたら、なぜか?失敗。。。
試しに 01_logostic_regressionのファイルを開いたら開けたので、再度、 02_binary_cnn 作成されたh5ファイルを開いたら、今度は成功!
そして、こちら↓がファイルを開いた画面
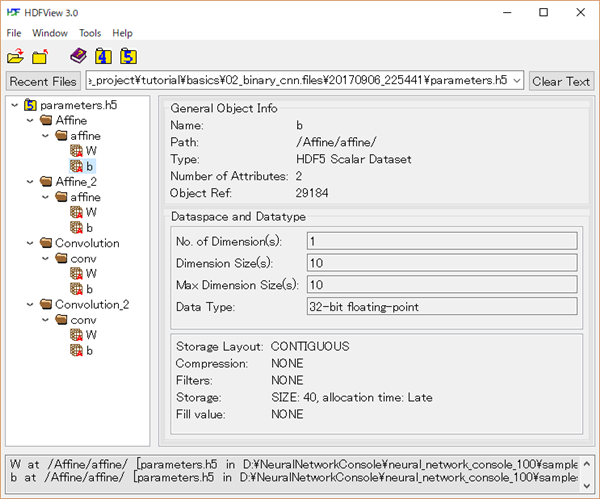

重みっぽいのがいる~!
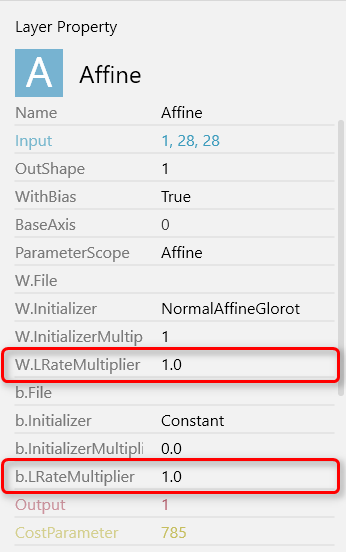
試しに最初のaffineのWの部分をダブルクリックすると、その部分の重みがExcelのような画面で表示されます。
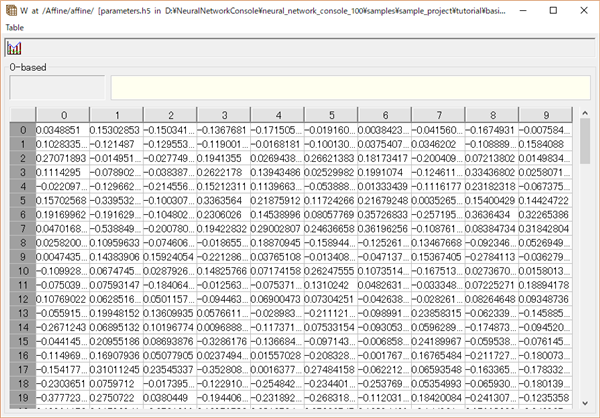

このパラメータはこの↓ニューラルネットの最初の Affine の部分の重みで


入力が8 x 4 x 4 = 128個で出力が10個になっているので、確かにつじつまも合う!
このパラメータが分かってしまえば、層の浅いニューラルネットワークであれば、単純に画像のフィルタ処理のノリでプログラムに落とし込めそう!!
とはいっても、次は、出力されたニューラルネットワークと、このh5ファイルを使って、プログラム(できればC++)に落とし込む方法を調べてみようと思っています。
(詳しい方がいれば、参考になるページ等、教えて下さい!)