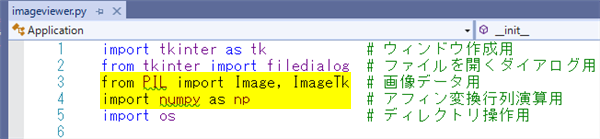
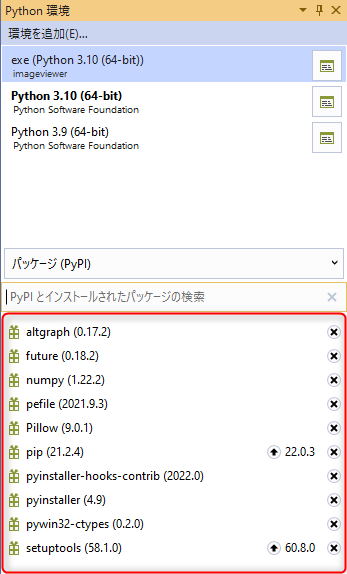
フォルダに格納された画像ファイルの一覧を取得する場合など、フォルダのパスを指定してファイルの一覧を取得したい場合があります。
その場合に、Pythonでは主に3通りの方法があります。
- glob.glob
検索条件を指定してファイル、フォルダ一覧を取得
- os.listdir
フォルダ内のファイル、フォルダ一覧を取得
- os.scandir
フォルダ内のファイル、フォルダ一覧をファイルか?フォルダか?の属性付きで取得
試しに以下のようなファイル、フォルダ構成の時に、どのようにファイル、フォルダを取得できるのか?をみていきたいと思います。
└─images
├─annotation.csv
├─0
│ ├─img0001.bmp
│ ├─img0001.png
│ ├─img0002.png
│ └─img0003.png
├─1
│ ├─img0101.png
│ ├─img0102.png
│ └─img0103.png
└─2
├─img0201.png
├─img0202.png
└─img0203.png
glob.glob
指定したフォルダ内において、検索条件を指定してファイル、フォルダ一覧を取得。
最も使いやすいと思います。
(サンプル)
import glob
files = glob.glob("./images/*")
print(files)
# ['./images\\0', './images\\1', './images\\2', './images\\annotation.csv']
files = glob.glob("./images/*.*")
print(files)
# ['./images\\annotation.csv']
files = glob.glob("./images/0/*.png")
print(files)
# ['./images/0\\img0001.png', './images/0\\img0002.png', './images/0\\img0003.png']
files = glob.glob("./images/**", recursive=True)
print("recursive", files)
# ['./images\\', './images\\0', './images\\0\\img0001.bmp', './images\\0\\img0001.png', './images\\0\\img0002.png', './images\\0\\img0003.png', './images\\1', './images\\1\\img0101.png', './images\\1\\img0102.png', './images\\1\\img0103.png', './images\\2', './images\\2\\img0201.png', './images\\2\\img0202.png', './images\\2\\img0203.png', './images\\annotation.csv']#
検索条件に * を指定すると、フォルダ内のファイル、フォルダ全てを取得します。
検索条件に *.* を指定すると、フォルダ内のファイルを取得します。ただし、フォルダ名に . が含まれる場合は、そのフォルダも取得します。
検索条件に *.png のように指定すると、指定した拡張子のファイルを取得します。
検索条件に ** を指定し、さらに、recursive=True と指定すると、指定したフォルダ以下(子のフォルダ内を含む)のファイル、フォルダ全てを取得します。
詳細はこちら↓のページを参照ください。
https://docs.python.org/ja/3/library/glob.html?highlight=glob#glob.glob
os.listdir
指定したフォルダ内のファイル、フォルダを取得します。
(サンプル)
import os
files = os.listdir("./images")
print(files)
# ['0', '1', '2', 'annotation.csv']
files = os.listdir("./images/0")
print(files)
# ['img0001.bmp', 'img0001.png', 'img0002.png', 'img0003.png']
os.listdirではファイル、フォルダの区別なく、指定したフォルダ内のファイル、フォルダの一覧を取得します。
取得した一覧からファイルか?フォルダか?を判断するにはos.path.isfile()メソッド、os.path.isdir()メソッドを使って以下のように行うことも可能です。
import os
files = os.listdir("./images")
for f in files:
path = os.path.join("./images", f)
if os.path.isfile(path):
# ファイルの場合
print("[file ]", f)
if os.path.isdir(path):
# ファイルの場合
print("[folder]", f)
# [Dir ] 0
# [Dir ] 1
# [Dir ] 2
# [File] annotation.csv
詳細はこちら↓のページを参照ください。
https://docs.python.org/ja/3/library/os.html?highlight=os%20listdir#os.listdir
os.scandir
指定したフォルダ内のファイル、フォルダをファイルか?フォルダか?の属性付きで取得します。
os.listdirではファイル、フォルダの一覧を取得後にファイルか?フォルダか?を判断しましたが、os.scandirでは、取得時に属性付きで取得します。
(サンプル)
import os
with os.scandir("./images") as it:
for entry in it:
if entry.is_file():
print("[file ]", entry.name)
elif entry.is_dir():
print("[folder ]", entry.name)
# [Dir ] 0
# [Dir ] 1
# [Dir ] 2
# [File] annotation.csv
あまり使用する機会が少ないのですが、フォルダ構成のまま、ファイルを取得した場合など、再帰的に呼び出すとフォルダ構成を取得できると思います。
詳細はこちら↓のページを参照ください。
https://docs.python.org/ja/3/library/os.html?highlight=os%20listdir#os.scandir