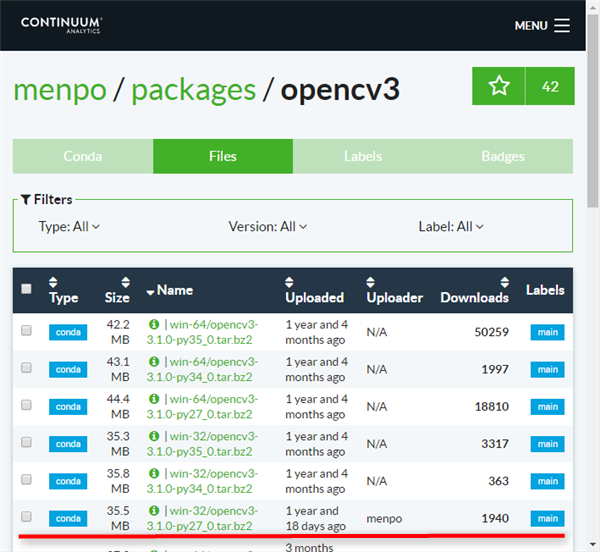
ここでは、ヒストグラムの取得方法と、取得したヒストグラムをmatplotlibで表示する方法を紹介したいと思います。
ヒストグラムの取得方法
OpenCVでヒストグラムを取得するには calcHist()関数を用います。
calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]]) ->hist| 引数 | 説明 |
| images | 画像の配列を指定します。 cv2.split()関数でB, G, Rのカラープレーンに分離した3枚の画像なども指定できます。 |
| channels | ヒストグラムを取得する色のチャンネル(B, G, Rのどれか?)を指定します。 グレースケールの場合は [0] B の場合は [0] G の場合は [1] R の場合は [2] を指定します。 |
| mask | ヒストグラムを取得する領域のマスク画像を指定します。 画像全体のヒストグラムを取得する場合は None を指定します。 |
| histSize | ヒストグラムのビンの数を指定します。通常は[256]となります。 |
| ranges | ヒストグラムを取得する輝度値の範囲を指定します。 通常は[0, 256]です。 |
| (戻り値)hist | 指定したチャンネルのヒストグラムを取得します。 |
サンプルプログラム
import cv2
# 画像の読込
img = cv2.imread("Parrots.bmp",cv2.IMREAD_UNCHANGED)
if len(img.shape) == 3:
# カラーのとき
channels = 3
else:
# モノクロのとき
channels = 1
histogram = []
for ch in range(channels):
# チャンネル(B, G, R)ごとのヒストグラム
hist_ch = cv2.calcHist([img],[ch],None,[64],[0,256])
histogram.append(hist_ch[:,0])# 次元を削除して追加
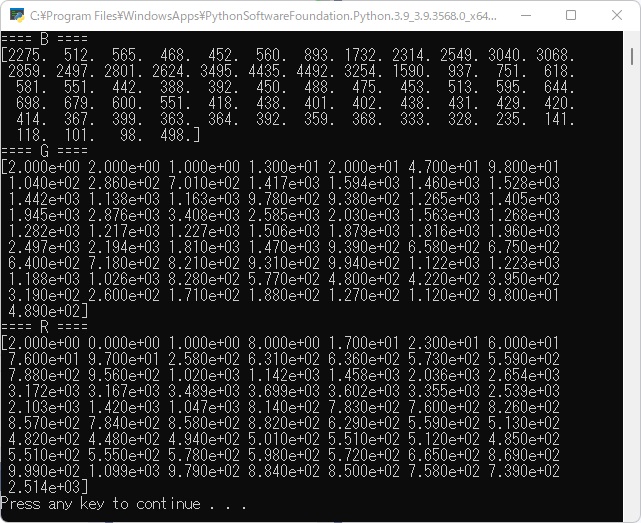
print("==== B ====")
print(histogram[0])
print("==== G ====")
print(histogram[1])
print("==== R ====")
print(histogram[2])※今回は、ビンの数を64にしました。
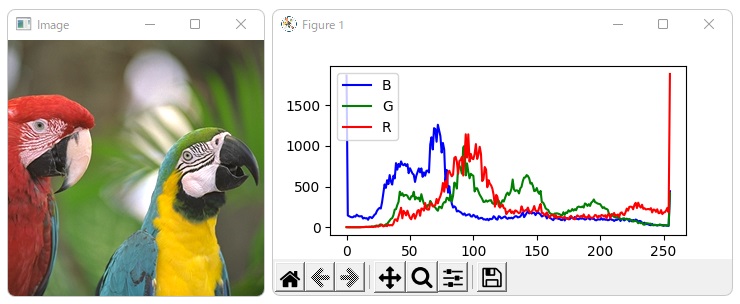
実行結果

matplotlibでヒストグラムの表示
ヒストグラムの表示については、Pillowを使って、ヒストグラムの取得、表示する方法を行いました。
Pillowでは色の順番がR, G, B の順ですが、 OpenCVは B, G, R の順なので、注意してください。
せっかくなので、ヒストグラムを取得する部分と、ヒストグラムを表示する部分は関数にしてみました。
import cv2
import matplotlib.pyplot as plt # ヒストグラム表示用
def get_histogram(img):
'''ヒストグラムの取得'''
if len(img.shape) == 3:
# カラーのとき
channels = 3
else:
# モノクロのとき
channels = 1
histogram = []
for ch in range(channels):
# チャンネル(B, G, R)ごとのヒストグラム
hist_ch = cv2.calcHist([img],[ch],None,[256],[0,256])
histogram.append(hist_ch[:,0])
# チャンネルごとのヒストグラムを返す
return histogram
def draw_histogram(hist):
'''ヒストグラムをmatplotlibで表示'''
# チャンネル数
ch = len(hist)
# グラフの表示色
if (ch == 1):
colors = ["black"]
label = ["Gray"]
else:
colors = ["blue", "green", "red"]
label = ["B", "G", "R"]
# ヒストグラムをmatplotlibで表示
x = range(256)
for col in range(ch):
y = hist[col]
plt.plot(x, y, color = colors[col], label = label[col])
# 凡例の表示
plt.legend(loc=2)
plt.show()
######################################################################
# 画像の読込
img = cv2.imread("Parrots.bmp",cv2.IMREAD_UNCHANGED)
# 画像の表示
cv2.imshow("Image", img)
# ヒストグラムの取得
hist = get_histogram(img)
# ヒストグラムの描画
draw_histogram(hist)実行結果