アフィン変換については、こちら↓のページ
アフィン変換(平行移動、拡大縮小、回転、スキュー行列)
で、紹介していますが、回転や拡大縮小、平行移動などは3行3列の行列を使った同次座標系を用いるのが便利ですよ!
と言っているのですが、OpenCVでは、2行3列の行列を使ったアフィン変換となります。
アフィン変換では、平行移動だけ、回転移動だけ、拡大縮小だけ、などということも少なく、平行移動、回転、拡大縮小などのアフィン変換を組み合わせて、変換行列は行列の積で求めます。
しかしOpenCVで扱うアフィン変換は2行3列の行列なので、行列の積が計算できないので、個人的には少し不便に感じます。
特に平行移動がからむと、ちょっと難しくなります。
そこで、前半では標準的にOpenCVで出来る事を説明し、後半では3行3列の行列を使ったアフィン変換の方法を紹介したいと思います。
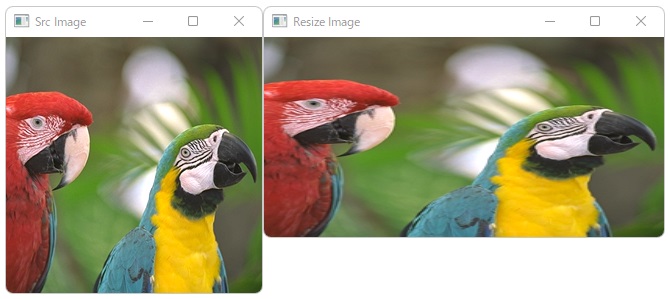
30°回転と0.8倍の縮小を行った例
import cv2
import affine
# 画像を読み込む
img = cv2.imread("image.bmp", cv2.IMREAD_UNCHANGED)
height, width, _ = img.shape
# 回転行列の取得
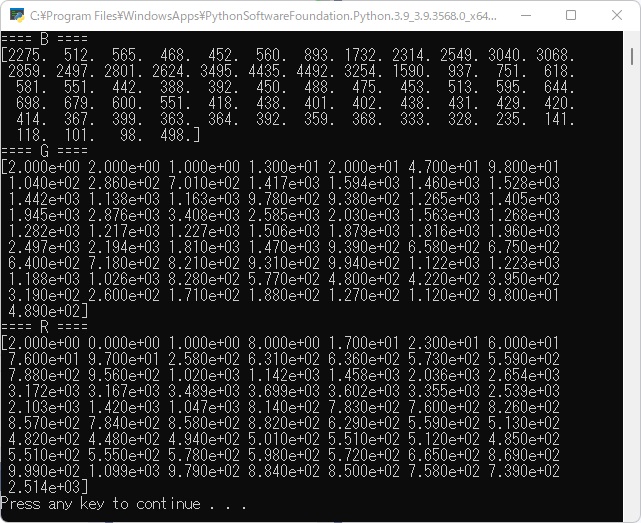
affineMatrix = cv2.getRotationMatrix2D((width/2, height/2), 30, 0.8)
print(affineMatrix)
# アフィン変換
img = cv2.warpAffine(img, affineMatrix, (width, height))
# 画像の表示
cv2.imshow("Image", img)
# キー入力待ち(ここで画像が表示される)
cv2.waitKey()
実行結果
OpenCVによるアフィン変換
OpenCVでは2行3列の行列を指定して、画像をアフィン変換するwarpAffine()関数と、
回転の中心座標、回転角度、倍率を指定してアフィン変換行列(2行3列)を取得するgetRotationMatrix2D()関数、
変換前の3点の座標と、対応する変換後の3点の座標を指定してアフィン変換行列(2行3列)を取得するgetAffineTransform() 関数が用意されています。
warpAffine()
画像のアフィン変換を行います。
warpAffine( src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]] ) -> dst
| 引数 |
説明 |
| src |
変換前の画像データ |
| M |
2行3列のアフィン変換行列 |
| dsize |
出力画像のサイズ (幅, 高さ) |
| dst |
borderMode = cv2.BORDER_TRANSPARENTのとき、背景画像を指定します。
ただし、dsizeとdstの画像サイズは同じにする必要があります。 |
| flags |
補間方法を指定します。
cv2.INTER_NEAREST
cv2.INTER_LINEAR
cv2.INTER_CUBIC
cv2.INTER_AREA
cv2.INTER_LANCZOS4
|
| borderMode |
ボーダー(画像からはみ出した部分)の設定を行います。
cv2.BORDER_CONSTANT (初期値)
cv2.BORDER_REPLICATE
cv2.BORDER_REFLECT
cv2.BORDER_WRAP
cv2.BORDER_TRANSPARENT |
| borderValue |
borderModeにcv2.BORDER_CONSTANTを指定したときの画像のはみ出した部分の輝度値を指定します。 初期値:0 |
| (戻り値)dst |
アフィン変換後の画像データ |
補間モード(flag)について
| cv2.INTER_NEAREST |
ニアレストネイバー |
| cv2.INTER_LINEAR |
バイリニア |
| cv2.INTER_CUBIC |
バイキュービック |
| cv2.INTER_AREA |
縮小のときにモアレが発生しないモード
公式ドキュメントには拡大のときはINTER_NEARESTと同じと書いてありますが、実際にやってみると、INTER_LINEARと同じと思われます。 |
| cv2.INTER_LANCZOS4 |
ランチョス |
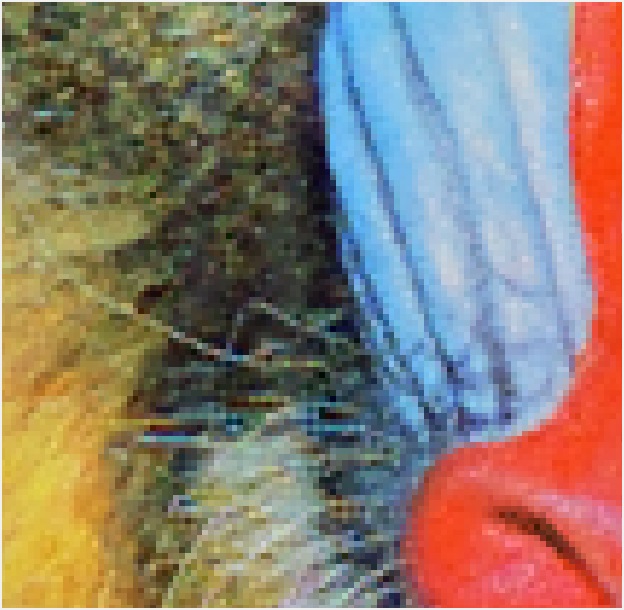
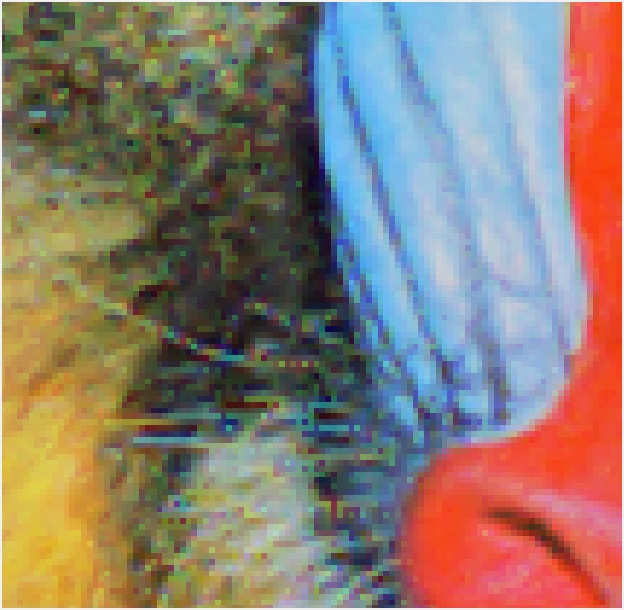
(元画像)目の部分を拡大したときの比較


 |
 |
 |
| INTER_NEAREST |
INTER_LINEAR |
INTER_CUBIC |
 |
 |
|
| INTER_AREA |
INTER_LANCZOS4 |
|
個人的な使い分けですが、画像処理結果を画像で見たいときはINTER_NEAREST、
画像処理の画像データとして、拡大縮小したいときはINTER_LINEAR、
写真のように見た目が大事なときはINTER_CUBIC
と、することが多いです。
(参考)
画素の補間(Nearest neighbor,Bilinear,Bicubic)の計算方法
borderMode(画像の外側の表示方法)について
| cv2.BORDER_CONSTANT |
borderValueで指定した色で埋めます。(初期値は黒) |
| cv2.BORDER_REPLICATE |
画像の一番外側の色で埋めます。 |
| cv2.BORDER_REFLECT |
画像を上下、左右方向にミラー反転して画像で繰り返し埋めます。 |
| cv2.BORDER_WRAP |
画像で繰り返し埋めます。 |
| cv2.BORDER_TRANSPARENT |
dstに出力画像と同じ大きさの画像を指定すると、画像の外側は透過して、画像の上に画像を配置します。 |
 |
 |
 |
| BORDER_CONSTANT |
BORDER_REPLICATE |
BORDER_REFLECT |
 |
 |
|
| BORDER_WRAP |
BORDER_TRANSPARENT |
|
getRotationMatrix2D()
基点(中心)周りに回転、拡大縮小を行うアフィン変換行列(2行3列)を取得します。
取得する行列は以下のようになります。
$$\begin{bmatrix}\alpha & \beta & (1-\alpha)\cdot center.x-\beta \cdot center.y \\-\beta & \alpha & \beta \cdot center.x + (1-\alpha )\cdot center.y \end{bmatrix}$$
ただし、
$$\begin{cases}\alpha=scale\cdot cos(angle)\\ \beta =scale\cdot sin(angle)\end{cases}$$
getRotationMatrix2D( center, angle, scale ) -> retval
| 引数 |
説明 |
| center |
回転、拡大縮小の基点(中心)となる(x,y)座標 |
| angle |
回転角度を度で指定します。 反時計周りが正 |
| scale |
拡大縮小する倍率を指定します。 |
| (戻り値)retval |
(x,y)座標を基点に回転、拡大縮小したときの2行3列のアフィン変換行列を取得します。 |
getAffineTransform()
アフィン変換前の3点の座標と、それに対応したアフィン変換後の3点の座標を指定して、アフィン変換行列を求まます。
getPerspectiveTransform( src, dst) -> retval
| 引数 |
説明 |
| src |
アフィン変換前の3点の(x,y)座標 |
| dst |
アフィン変換前の点に対応したアフィン変換後の3点の(x,y)座標 |
| (戻り値)retval |
2行3列のアフィン変換行列 |
3行3列の行列を使ったアフィン変換
OpenCVでは、2行3列の行列を用いてアフィン変換を行うので、同次座標系の特徴でもある、平行移動も含めて行列の積でアフィン変換の行列を求めることができません。
そこで、回転、拡大縮小、平行移動の3行3列の行列は自作で作って、実際に画像をアフィン変換する部分はwarpAffine()関数のアフィン変換行列の部分に3行3列の行列をスライスして2行3列の行列として渡す方針でやってみたいと思います。
3行3列のアフィン変換行列を求める部分はファイル(affine.py)にまとめました。
# affine.py
import cv2
import numpy as np
def scaleMatrix(scale):
'''拡大縮小用アフィン変換行列の取得(X方向とY方向同じ倍率)'''
mat = identityMatrix() # 3x3の単位行列
mat[0,0] = scale
mat[1,1] = scale
return mat
def scaleXYMatrix(sx, sy):
'''拡大縮小用アフィン変換行列の取得(X方向とY方向の倍率をぞれぞれ指定)'''
mat = identityMatrix() # 3x3の単位行列
mat[0,0] = sx
mat[1,1] = sy
return mat
def translateMatrix(tx, ty):
'''平行移動用アフィン変換行列の取得'''
mat = identityMatrix() # 3x3の単位行列
mat[0,2] = tx
mat[1,2] = ty
return mat
def rotateMatrix(deg):
'''回転用アフィン変換行列の取得'''
mat = identityMatrix() # 3x3の単位行列
rad = np.deg2rad(deg) # 度をラジアンへ変換
sin = np.sin(rad)
cos = np.cos(rad)
mat[0,0] = cos
mat[0,1] = -sin
mat[1,0] = sin
mat[1,1] = cos
return mat
def scaleAtMatrix(scale, cx, cy):
'''点(cx, cy)を基点とした拡大縮小用アフィン変換行列の取得'''
# 基点の座標を原点へ移動
mat = translateMatrix(-cx, -cy)
# 原点周りに拡大縮小
mat = scaleMatrix(scale).dot(mat)
# 元の位置へ戻す
mat = translateMatrix(cx, cy).dot(mat)
return mat
def rotateAtMatrix(deg, cx, cy):
'''点(cx, cy)を基点とした回転用アフィン変換行列の取得'''
# 基点の座標を原点へ移動
mat = translateMatrix(-cx, -cy)
# 原点周りに回転
mat = rotateMatrix(deg).dot(mat)
# 元の位置へ戻す
mat = translateMatrix(cx, cy).dot(mat)
return mat
def afiinePoint(mat, px, py):
'''点(px, py)をアフィン変換行列(mat)で変換した後の点を取得'''
srcPoint = np.array([px, py, 1])
return mat.dot(srcPoint)[:2]
def inverse(mat):
'''行列の逆行列を求める'''
return np.linalg.inv(mat)
def identityMatrix():
'''3x3の単位行列を取得'''
return np.eye(3, dtype = np.float32) # 3x3の単位行列
使い方としては、上記のプログラムをaffine.pyというファイルに保存して、使う側のプログラムと同一フォルダに配置し、
のようにすれば、使えるようになります。
例えば、OpenCVのgetRotationMatrix2D()関数で行っていることは、
中心座標を原点へ平行移動
↓
拡大縮小
↓
回転(マイナス方向)
↓
原点から中心へ平行移動
となっていて、この順番でアフィン変換の行列の積を行えば、行列が求まります。
getRotationMatrix2D()関数と同じアフィン変換行列を求めるサンプル
import cv2
import affine # affine.pyファイルを同一フォルダに置くこと
# 中心座標
cx = 100
cy = 5
# 回転角度
angle = 30
# 拡大縮小
scale = 0.8
# OpenCVのgetRotationMatrix2D()関数と同等のアフィン変換行列を求める
matAffine = affine.translateMatrix(-cx, -cy) # 原点へ平行移動
matAffine = affine.scaleMatrix(scale).dot(matAffine) # 拡大縮小
matAffine = affine.rotateMatrix(-angle).dot(matAffine) # 回転
matAffine = affine.translateMatrix(cx, cy).dot(matAffine) # 中心へ戻す
print(matAffine)
#[[ 0.6928203 0.4 28.717972 ]
# [-0.4 0.6928203 41.5359 ]
# [ 0. 0. 1. ]]
# OpenCVのgetRotationMatrix2D()関数を実行し、求めたアフィン変換行列が上記と一致している事を確認
matAffine_cv = cv2.getRotationMatrix2D((cx, cy), angle, scale)
print(matAffine_cv)
#[[ 0.69282032 0.4 28.7179677 ]
# [-0.4 0.69282032 41.53589838]]
あとは、ここで求めたアフィン変換の行列を2行3列の行列にスライスして、warpAffine()関数へ渡せば、画像のアフィン変換ができます。
img = cv2.warpAffine(img, affineMatrix[:2,], (width, height))
例題)3x3画素の画像を100倍に拡大する
画像を拡大するとき注意が必要なのが、画素の中心が、小数点以下が0になる座標(X.0, X.0)だという事に注意してください。詳しくは以下のページを参照ください。
画像の拡大
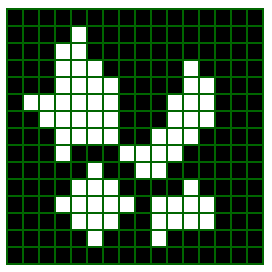
この事を知らずに、OpenCVのgetRotationMatrix2D()関数で3×3画素の市松模様の画像の拡大を行うと・・・
import numpy as np
import cv2
# 画像データ
img = np.array(
[[0, 255, 0],
[255, 0, 255],
[0, 255, 0],
],
dtype = np.uint8
)
# OpenCVでアフィン変換行列を求める
matAffine = cv2.getRotationMatrix2D(center=(0,0), angle=0, scale=100)
# アフィン変換
img = cv2.warpAffine(img, matAffine, (300, 300), flags = cv2.INTER_NEAREST)
# 画像の表示
cv2.imshow("Image", img)
# キー入力待ち(ここで画像が表示される)
cv2.waitKey()
実行結果

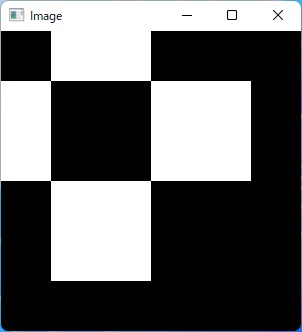
上図のように左上の画素の中心に拡大されるため、ズレた画像になってしまいます。
この100倍の拡大を3行3列のアフィン変換を使って行うには、どのように考えるかというと、
(+0.5, +0.5)の平行移動(画像の角を原点に合わせる)
↓
100倍の拡大
↓
(-0.5, -0.5)の平行移動(左上の画素の中心を原点に合わせる)
というように変換を行います。
import numpy as np
import cv2
import affine # afiine.py のファイルが同一フォルダにあること
# 画像データ
img = np.array(
[[0, 255, 0],
[255, 0, 255],
[0, 255, 0],
],
dtype = np.uint8
)
# OpenCVでアフィン変換行列を求める
matAffine = affine.translateMatrix(0.5, 0.5) # 平行移動
matAffine = affine.scaleMatrix(100).dot(matAffine) # 100倍の拡大
matAffine = affine.translateMatrix(-0.5, -0.5).dot(matAffine) # 原点の位置へ移動
# アフィン変換
img = cv2.warpAffine(img, matAffine[:2,], (300, 300), flags = cv2.INTER_NEAREST)
# 画像の表示
cv2.imshow("Image", img)
# キー入力待ち(ここで画像が表示される)
cv2.waitKey()
実行結果
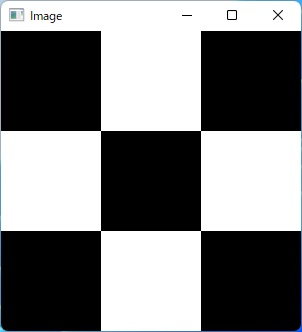
このサンプルのソースコードはここ↓へ置きましたので、ご自由にお使いください。
OpenCVAffineSample.zip
関連記事
アフィン変換(平行移動、拡大縮小、回転、スキュー行列)
画像の拡大
画素の補間(Nearest neighbor,Bilinear,Bicubic)の計算方法
任意点周りの回転移動(アフィン変換)
【Python/NumPy】座標からアフィン変換行列を求める方法