最近のPCではOSは64ビットで、搭載メモリも8GBぐらいは普通にあるので、C#のプログラムでもメモリを4GBぐらいは普通に確保できそうですが、実際には2BGぐらいで頭打ちになります。
おそらくメモリサイズ(要素数)を計算するときにint型で計算していてint型の最大値(2,147,483,647)を超える事でエラーになる場合が多そうです。
そこで、試しにメモリ確保の処理(配列、Bitmapクラス、Marshal.AllocCoTaskMem)の最大値が、どの程度まで確保できるのか?を確認してみました。
評価環境
- Windows11 Home 64bit
- 搭載メモリ 32GB
- Visual Studio 2019
- C#(.NET Core 3.1)
配列の最大値
よく使うbyte, int, float, doubleの型で試してみたところ、以下の要素数が最大となりました。
var byteArr = new byte[2147483591];
var intArr= new int[2146435071];
var floatArr= new float[2146435071];
var doubleArr= new double[2146435071];配列の最大値に関しては、メモリのサイズというよりも、要素数のint型の最大値制限になっているようです。
.NET Frameworkの場合、デフォルトでは最大サイズが異なるようです。
詳細は、下記ページを参照ください。
https://docs.microsoft.com/ja-jp/dotnet/framework/configure-apps/file-schema/runtime/gcallowverylargeobjects-element?redirectedfrom=MSDN
Bitmapクラスの最大値
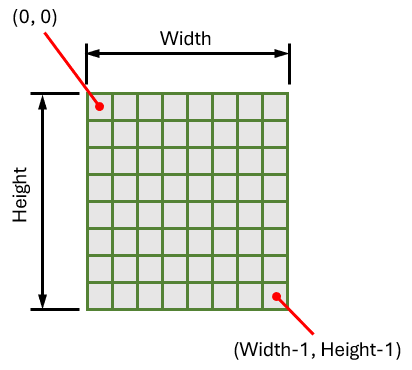
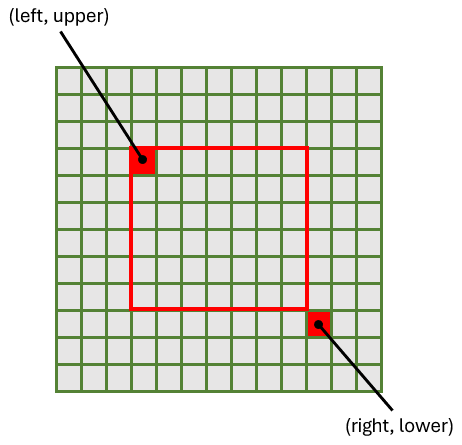
Bitmapクラスの確保には、幅、高さ、PixelFormatの組み合わせが、いろいろできてしまうため、幅の値は固定して、高さを変えながらエラーが出るまで最大の高さを確認しました。
以下が、PixelFormatをFormat8bppIndexed, Format24bppRgb, Format32bppArgbで確認したときの最大のサイズとなります。
var bmp8 = new Bitmap(1024 * 3, 699049, System.Drawing.Imaging.PixelFormat.Format8bppIndexed);
var bmp24 = new Bitmap(1024, 699049, System.Drawing.Imaging.PixelFormat.Format24bppRgb);
var bmp32 = new Bitmap(1024, 524287, System.Drawing.Imaging.PixelFormat.Format32bppArgb);Bitmapクラスに関しては、 幅 x 高さ x 画素のバイト数(1, 3, 4) の値がint型の最大値に引っかかっているようです。
AllocCoTaskMemの最大値
あまり使う機会はありませんが、メモリ確保で使われるAllocCoTaskMemについても調べてみました。
var ptr = System.Runtime.InteropServices.Marshal.AllocCoTaskMem(2147483647);こちらは、AllocCoTaskMemの引数がint型のため、最大値を超えるとビルド時にエラーとなります。
まとめ
C#のメモリの最大値について調べてみましたが、おおむね2GBの制限があります。
メモリのサイズというより、要素数のint型の最大値(2,147,483,647)を超える事によりエラーになっているようです。
今時のPCで、2GBしかメモリを確保できないだなんて。。
1つのプロセス(実行しているプログラム)で2GB以下のメモリを複数確保する事は可能です。
どうしても2GB以上のメモリを確保したい場合は、メモリを分割して処理するか、C言語ライブラリを作成して、メモリ管理をライブラリ側で行う事で可能になります。
ただし、この時にも、うっかりint型で width * height * ch みたいな計算をしてしまうと、int型の最大値を超えてしまうので、要素数やメモリサイズを計算するときの型には注意が必要です。
参考
https://docs.microsoft.com/ja-jp/dotnet/csharp/language-reference/builtin-types/integral-numeric-types