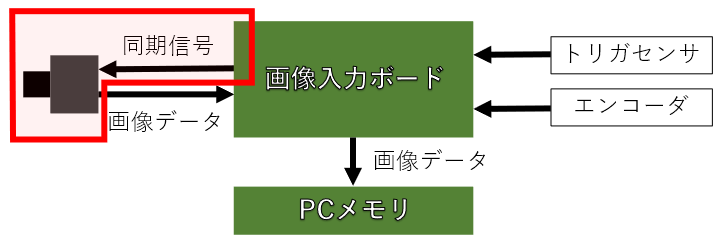
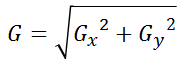画像入力ボードは、主に工業用のカメラを用いる時に、PCのスロットに刺して用いられます。
他にもフレームグラバ(frame grabber)やキャプチャボードと言ったりもしますが、キャプチャボードと言うと、民生品のビデオキャプチャボードを指す場合が多いので、私は画像入力ボードと言うようにしています。
画像入力ボードでは、一般的なWebカメラなどとは違って、様々な設定が出来る分だけ、ハマりやすいポイントもあるので、そのへんの勘所をまとめてみたいと思います。
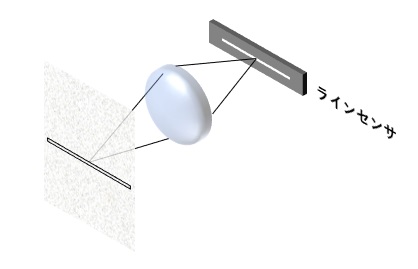
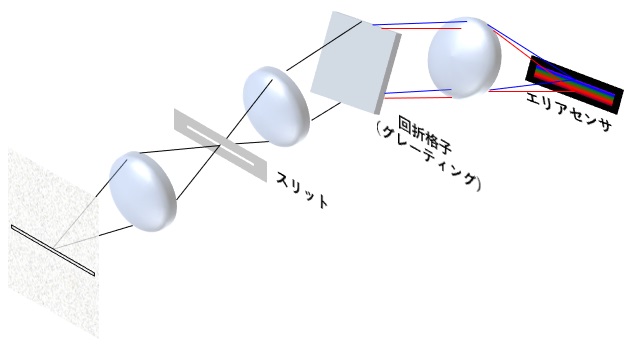
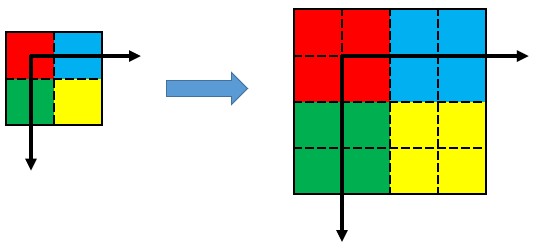
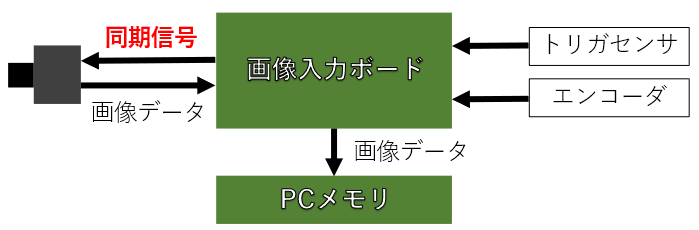
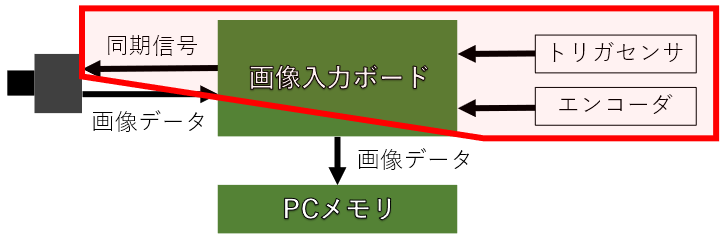
まずは画像入力ボードを使った一般的なシステムを以下に示します。

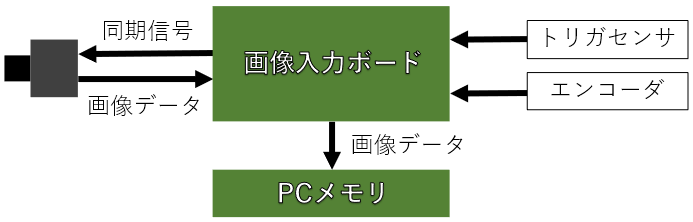
画像入力ボードへは、移動する被写体の動きに合わせて撮影できるように、光電センサなどのトリガセンサの信号を入力したり、ベルトコンベアなどのような搬送系を用いる場合は、搬送速度のムラにも対応するためにエンコーダを接続します。
このトリガ信号やエンコーダ信号を用いて、画像入力ボードは同期信号を生成し、カメラへ送ります。
この同期信号では、カメラで撮影する画像の各フレーム1枚1枚の撮影タイミング(ラインセンサの場合は、各ラインの撮影タイミング)や露光時間を制御します。
工業用のカメラでは、この同期信号に連動して撮影できる事が大きな特徴ですが、この同期信号の事をCameraLinkというカメラの接続規格では Camera Control信号(略:CC信号)といいます。
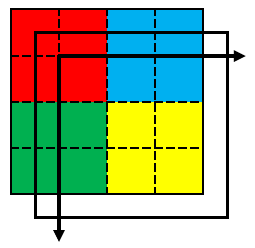
さらに、カメラで撮影された画像データは一般的な画像データのように画像の左上から整然と輝度データは出力されない場合もあるので、画像入力ボードで画像の輝度データを整列し、PCのメモリへ格納します。
一般的なWebカメラと工業用カメラとの違い
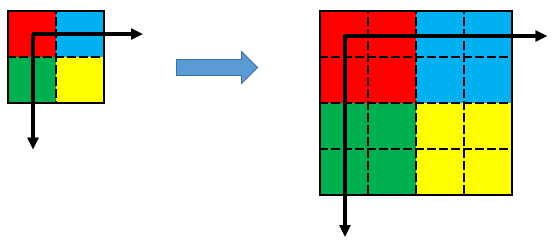
一般的なWebカメラでは以下のような以下のような構成になります。

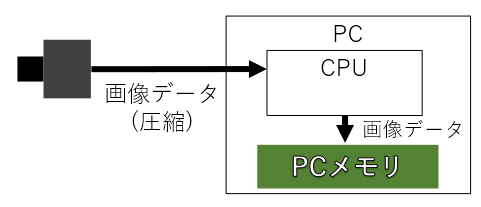
上図のように、一般的なWebカメラでは同期信号の入力がありません。
このことは、例えば30fpsのカメラでは、1/30秒ごとに画像の撮影しています。
この状態で移動する被写体を撮影すると、1/30秒ごとに被写体が画像の中心にあるとは限らないため、被写体の撮影位置がバラバラな状態になってしまいます。

(撮影画像)


これは、たとえIOボードを用いてトリガセンサを繋いだとしても、同期信号が無いと、各フレームの撮影タイミングは制御できないため、撮影位置がバラバラになってしまいます。
さらに画像データは圧縮されてUSBを介してPCへ転送され、CPUで画像データをデコードし、画像データをPCのメモリへ配置される場合もあるため、CPUに負荷がかかります。
また、データ圧縮は非可逆となる場合も多く、細かい欠陥を検査するような場合の用途では不向きです。
カメラの設定とボードの設定がある
画像入力ボードを使ってカメラの画像を撮影するには、カメラとボードの設定を、それぞれ行う必要があります。主な設定値には以下のようなものがあります。
| カメラの設定 |
ボードの設定 |
画像の幅
画像の高さ
同期モード(内部、外部)
フレームレート(スキャンレート)
露光時間
ゲイン
オフセット |
画像の幅
画像の高さ
同期信号出力の有効/無効
フレームレート(スキャンレート)
露光時間
トリガの有効/無効
エンコーダの設定 |
上記のように、似た設定がカメラとボードの両方にあるので、最初は混乱しやすいのですが、ちゃんと把握しておく必要があります。
画像の幅、高さ
カメラの画像の幅と高さの設定は、カメラから画像入力ボードへ転送される画像のサイズで、画像入力ボードの幅と高さは、カメラから送られてきた画像から部分的に切り取るサイズとなります。
ラインセンサカメラの場合、カメラから出力される画像の高さは1となるため、ボードの設定の高さは何ライン分の画像データを1画面分の画像データとするか?の設定となります。
同期モード、同期信号出力設定
カメラの同期モードの設定は、各フレームの撮影タイミング、露光時間をカメラ自身のタイミングで撮影する設定(フリーラン、自走モード)と、画像入力ボードから送られてきた同期信号に基づいて撮影する設定とがあります。前者の設定を内部同期、フリーラン、自走モードなどと言い、後者の設定を外部同期、ランダムシャッタなどを言います。
ボードの同期信号出力の設定は、画像入力ボードからカメラへ同期信号を送るか?送らないか?の設定になりますが、ボードから同期信号を出力していても、その同期信号を使う/使わないの設定はカメラの設定となるため、通常、同期信号は出力する設定にしておきます。
フレームレート、露光時間
カメラのフレームレートと露光時間の設定は、カメラがフリーラン(自走モード)の時に、カメラに設定されたフレームレートと露光時間で動作し、カメラが外部同期の場合は、ボードに設定されたフレームレートと露光時間で動作します。
ゲイン、オフセット
ゲイン、オフセットの設定は、カメラのセンサに対して行う設定となるため、カメラ特有の設定となります。
トリガの有効/無効設定
トリガという言葉は、カメラへ送られる同期信号の事をトリガという場合もあるので、ややこしいのですが、撮影開始タイミングをフォトセンサなどを通過したタイミングで撮影する場合は、トリガの設定を有効にします。ただし、トリガを有効にする場合は、各フレームの撮影タイミングをトリガのタイミングに合わせる必要があるので、カメラの同期モードを外部同期モードにする必要がります。
エンコーダの設定
エンコーダ信号に同期して撮影する場合は、撮影開始のタイミングをエンコーダの何パルス後に撮影するか?の設定や、エンコーダ何パルスごとに撮影するか?の設定があります。
同期信号(CC信号)のしくみ
画像入力ボードから、カメラへ送られる同期信号のお話です。

同期信号は下図のような矩形波(パルス信号)がカメラへ送られます。

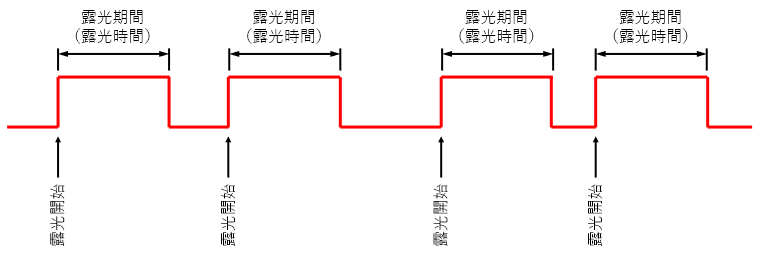
この矩形波をカメラが受けて、カメラがどうのような挙動をするか?は、カメラの機能やカメラの設定次第な部分もありますが、代表的な例としては、上図のように、同期信号の立ち上がり部分でカメラの露光を開始し、信号のHigh期間分、露光し、信号が立ち下がると画像データをPCへ転送します。あとは、この繰り返しです。
大事なのは、このCC信号により、カメラの各フレームの撮影タイミングと露光時間を制御できるという事です。
※カメラによってはHighとLowが逆の場合もあります。
同期信号(CC信号)の生成(画像入力ボードの動作、設定)
画像入力ボードではトリガセンサの信号やエンコーダ信号を受けて同期信号(CC信号)を生成しますが、トリガセンサを使う/使わない、エンコーダを使う/使わない設定により、いくつかのパターンがあります。

トリガ、エンコーダを使わない場合
画像入力ボードに同期信号の周期(フレームレート、スキャンレート)とHigh期間の時間(露光時間)を設定し、定期的にCC信号を出力します。


フレームレートと露光時間を画像入力ボード側で制御が可能となります。
ただし、実際にカメラで撮影されるフレームレートと露光時間はカメラの設定次第となります。
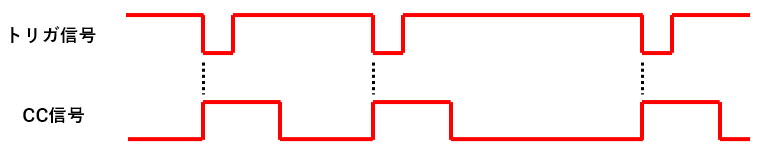
トリガを使用し、エンコーダを使用しない場合
トリガ信号を有効にし、エンコーダを無効にする撮影は、ベルトコンベアのようなライン上を流れてくる被写体をエリアセンサで撮影する場合に、よく用いられます。
トリガ信号が画像入力ボードに入力されたら、CC信号を1パルス分出力します。
設定によりトリガ1パルスにつき、何パルスか出力する設定する事も可能です。
また、トリガ信号の立下りから、実際にCC信号が出力されるまでの時間を調整する事も可能です。

トリガ、エンコーダを使用する場合
ラインセンサの場合は、エンコーダ信号と同期させる場合が多くあります。
下図のように、トリガ信号が入力されたら、指定パルス数分遅らせてから最初のCC信号を出力します。
次のCC信号は、指定パルス数分のエンコーダパルスごとにCC信号を出力します。
下図の例では、トリガ信号入力後、8パルス後にCC信号を出力し、以降は4パルスおきにCC信号を出力する例です。

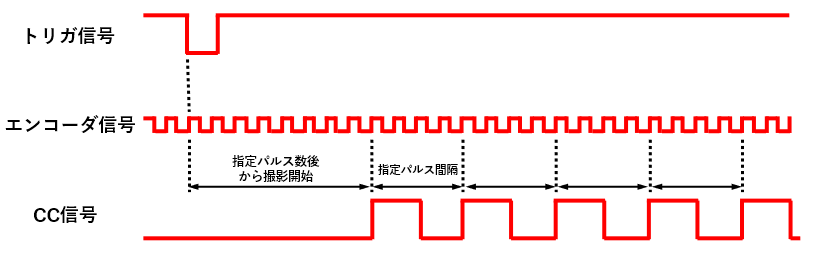
ただし、エンコーダ信号はA相、B相の両方をカウントして、エンコーダの呼称パルス数の2倍でカウントする2逓倍と呼ばれるカウント方法やA相、B相の立ち上がり、立下りをカウントし、4倍でカウントする4逓倍のカウント方法があります。
CC信号による同期撮影(カメラの動作、設定)
前項目の同期信号の生成では、画像入力ボードがどのような同期信号を生成するか?の話であって、実際にカメラがどうように同期信号に基づいて撮影をするか?はカメラ側の設定次第となります。

同期信号(CC信号)を使用しない場合
カメラに設定したフレームレートと露光時間に基づいて生成した信号に同期してセンサを露光します。
この設定を内部同期 や フリーランと呼びます。

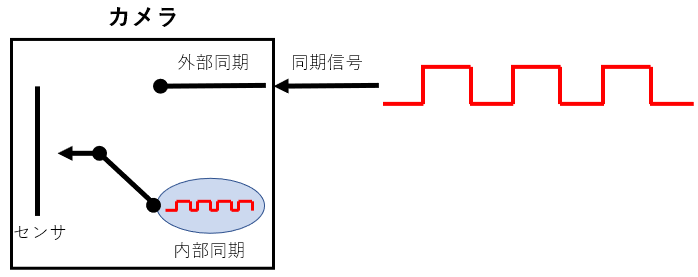
通常、カメラの初期値では、このフリーラン状態設定されています。
同期信号(CC信号)を使用する場合
カメラの外部(画像入力ボード)で生成された同期に同期してセンサを露光します。
この設定を外部同期 などと言います。

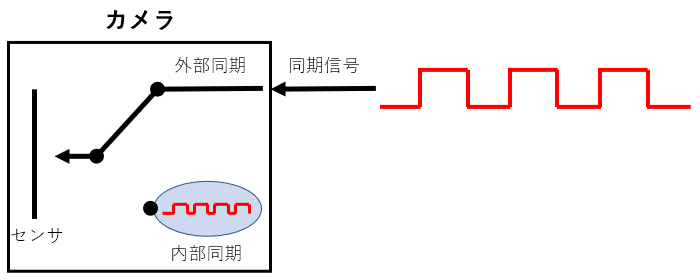
この設定を使用するには、カメラの設定をしないといけないのですが、「外部同期」という言葉はカメラメーカーによって、まちまちなため、最初は戸惑うと思います。(私も毎回戸惑ってます。。)
この外部同期で撮影しているつもりで、画像入力ボードの露光周期(フレームレート、スキャンレート)と露光時間を変更しても撮影した画像の明るさやフレームレートが変化しないな?と思ったら、まずは、カメラが外部同期の設定になっているかどうかを確かめて下さい。
様々な同期撮影モード
画像入力ボードは同期信号を生成してカメラへ入力しますが、その同期信号に基づいて、どのような露光時間で撮影するか?はカメラによっては、いくつかのモードがある場合があります。(モードが無い場合もあります。)
最初の方で説明したように、露光時間とフレームレート(スキャンレート)の設定は、カメラとボードのそれぞれに存在します。
この露光時間とフレームの設定を、どちらの設定を使うか?は、カメラ側の設定(露光モードなどと言われる)で決まります。
同期信号(CC信号)のHight期間分だけ露光するモード
比較的一般的な撮影モードです。
CC信号の立ち上がりから露光を開始し、CC信号がHigh期間分だけ露光をします。

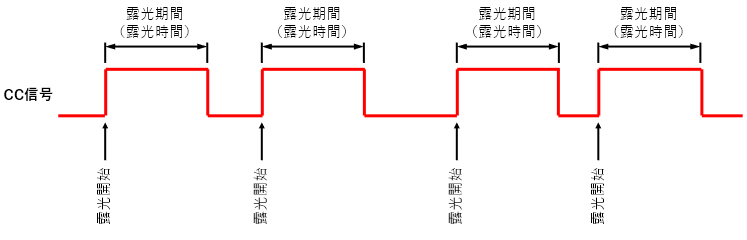
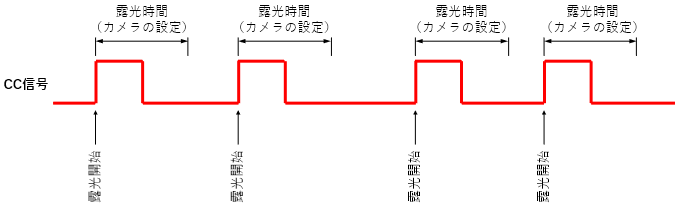
カメラに設定された露光時間で露光するモード
ラインセンサカメラで比較的採用されているモードです。
CC信号の立ち上がりから露光を開始しますが、露光時間そのものは、カメラに設定された露光時間で露光します。

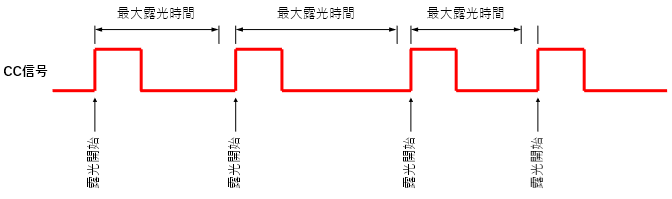
次の露光開始まで、可能な限りの最大露光時間で露光するモード
CC信号の立ち上がりから次の立ち上がりまでの間で可能な限りの露光時間で露光するモードです。
この事は、エンコーダと同期して撮影している場合、被写体の移動速度が変化すると、露光時間も変化してしまうので、使いづらいモードではあるのですが、TDIセンサでは、このモードになっている場合が多くあります。

ポイント!
カメラの最速フレームレート以上の周期でCC信号をカメラへ入力してはいけない
例えば、カメラの最速フレームレートが30fpsのカメラに1秒あたり50パルス(50fps相当)のCC信号をカメラへ入力してはいけません。
実際に必要以上にCC信号を入力してしまった場合、カメラが壊れる事はない?と思いますが、どのような挙動になるか?は使用するカメラによって異なるのですが、比較的多いパターンとしては
- 必要以上のCC信号のパルスが無視される。
→結果として、フレームレート、スキャンレートが想定以上に遅くなります。
ラインセンサカメラの場合、縦が縮んだ画像になります。
- 撮影した画像の一部が前のフレームの画像と混ざった画像になる。
- カメラが反応しなくなる。
など。。
この状態は、エンコーダと同期して撮影する際に陥る事がよくあります。
何かおかしい!と思った場合は、搬送速度を遅くする、CC信号の出力周期を遅くなるように設定するなどしてください。このように遅くしていくと、途中から正規のCC信号になった瞬間、フレームレートがカメラの最速の状態で撮影が出来るので、確認ができると思います。
ポイント!
カメラの露光時間以下の周期でCC信号を生成しようとしてはいけない
露光時間より短い間隔で撮影する事ができないのは、当たり前のように思われるかもしれませんが、エンコーダと同期して撮影すると陥りやすい状態です。
この状態になると、前項と同じような症状になるので、まずは搬送速度を遅くする、CC信号の出力周期を遅くするように試してみてください。
ポイント!
エンコーダと同期撮影では、ほぼ最速のフレームレート(スキャンレート)は出せない
これは何故??と思われるかもしれませんが、そもそも、なぜエンコーダと同期させて撮影しようとしているかというと、搬送速度がバラついても歪みの無い画像を撮影するためであって、エンコーダ信号にもバラつきがあります。
このような状態で、CC信号の周期が速くなるような設定を行うと、ところどころでカメラの最速フレームレート(スキャンレート)を超えてしまいます。
それでも、搬送速度にバラつきが無いので、最速で撮影したい!と言われる場合があるのですが、その時はエンコーダとの同期をしない(フリーランで撮影する)と、カメラの最速が狙えます。
まとめ
露光時間とフレームレートの設定の概念は、画像入力ボード側とカメラ側の両方(別々)にあります。
自分が内部同期で撮影したいのか?外部同期で撮影したいのか?明確に意識して両方の設定をしてください。
また、特にエンコーダと同期して撮影する場合には、カメラの最速フレームレート、スキャンレートを超えないように注意してください。
何かおかしいな?と思ったときは、まずはフレームレートを遅くするように、搬送速度を遅くする(エンコーダの周波数を下げる)、スキャンレートを遅くするなど、してみてください。
ボード側の設定を変えてもフレートレート(スキャンレート)に変化が無い場合は、カメラの設定が内部同期になっている可能性が高いですし、フレートレート(スキャンレート)を遅くする事で、実際にカメラで撮影したフレートレート(スキャンレート)が速くなる場合は、カメラの最速のフレートレート(スキャンレート)以上の設定をしていた可能性が高いです。
参考
https://faq-avaldata.dga.jp/faq_list.html?category=4
https://www.avaldata.co.jp/products/imaging/category/imageInputBoard