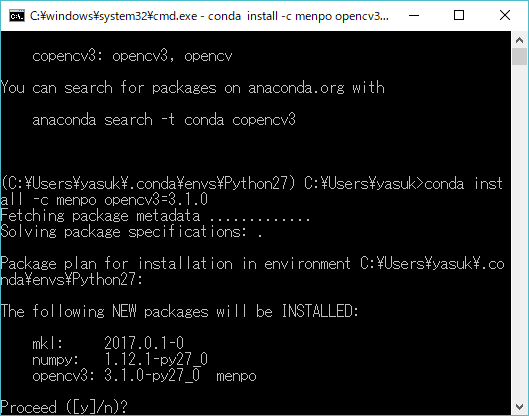
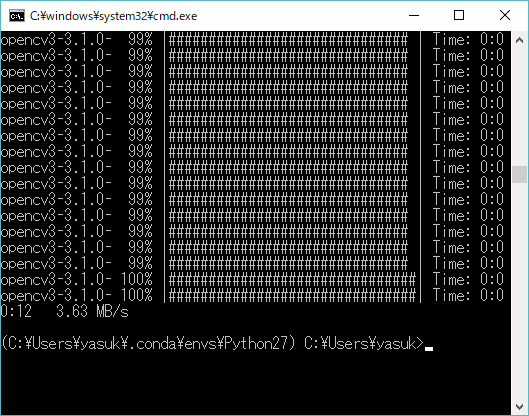
OpenCV(Python)で二値化された画像中の白の部分 findContours() 黒の部分
findContours()関数で取得できる情報は、輪郭を構成している点の座標群と輪郭の内側、外側の情報となります。
さらに、これらの情報を用いて、輪郭の長さや、輪郭の内側の面積、重心、輪郭部分の矩形領域などを取得できる関数も別途、用意されています。
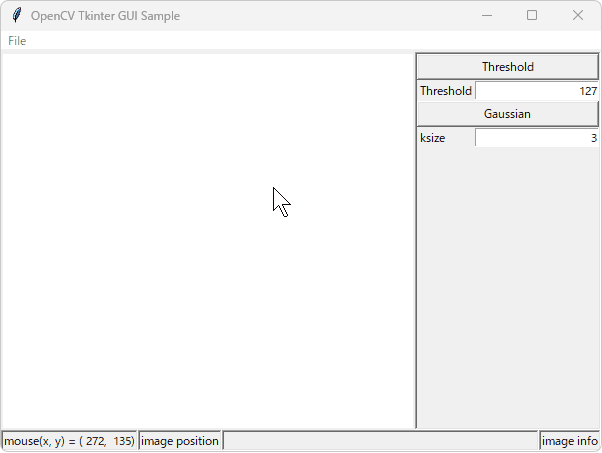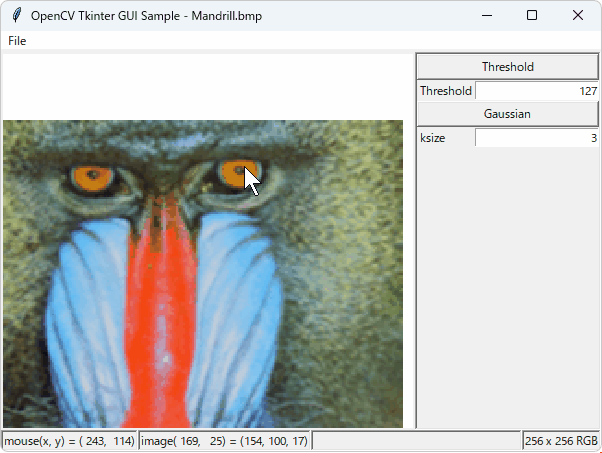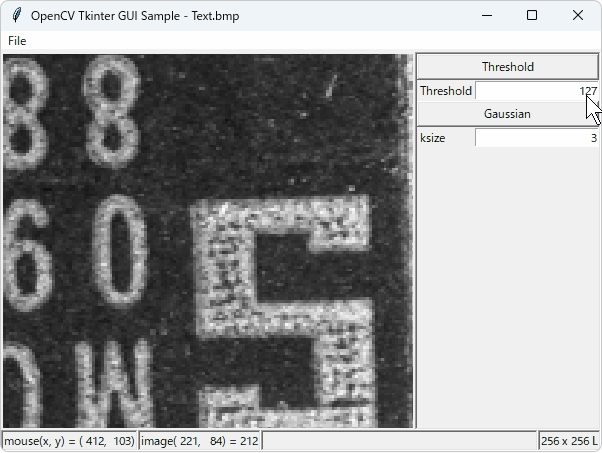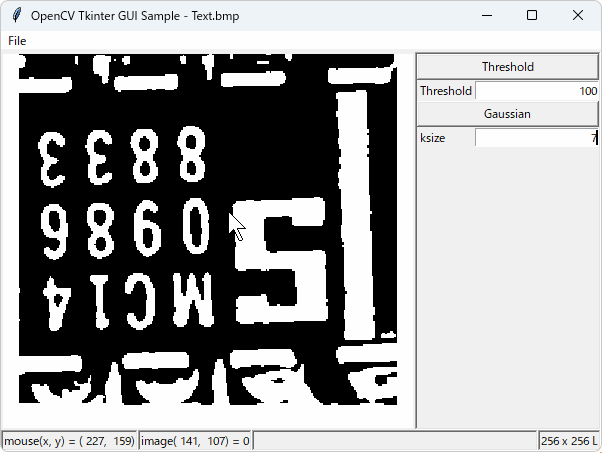
処理例
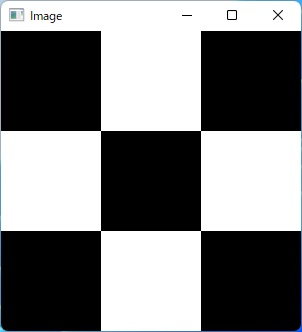
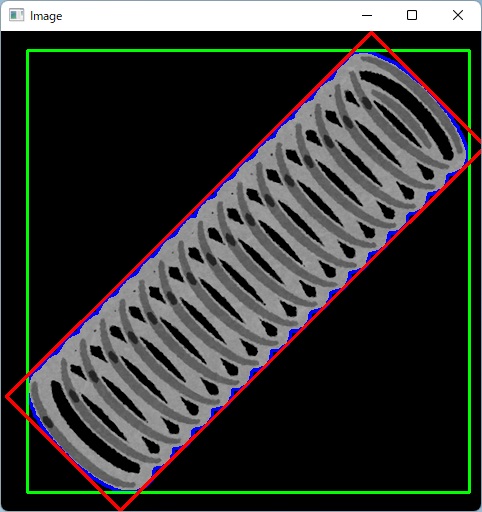
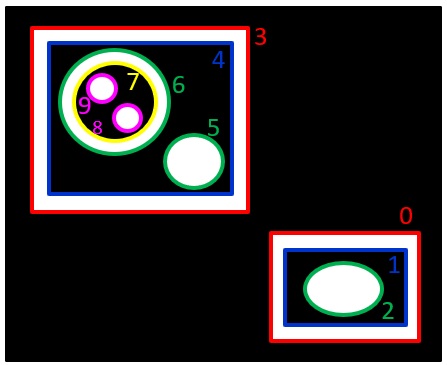
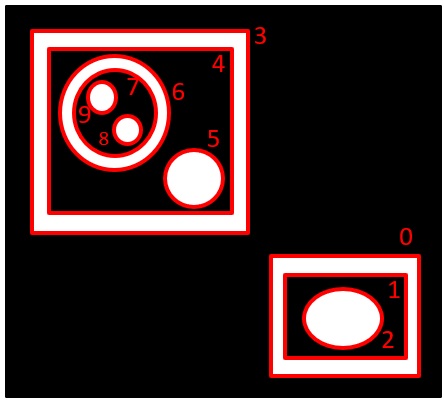
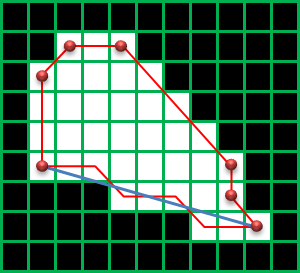
(入力画像)
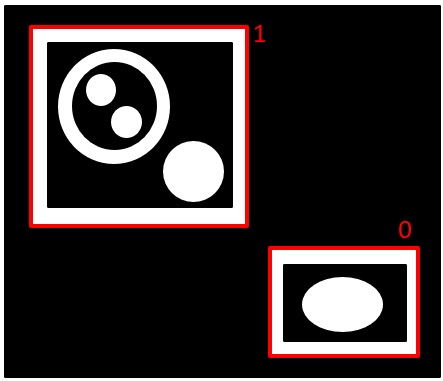
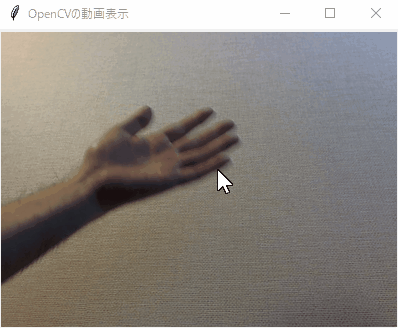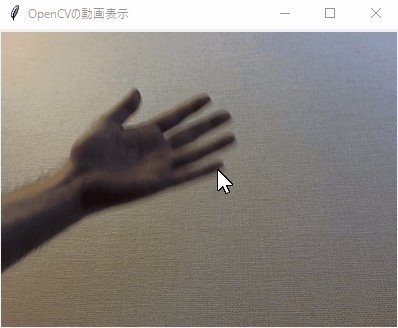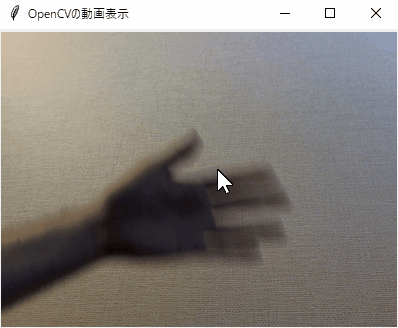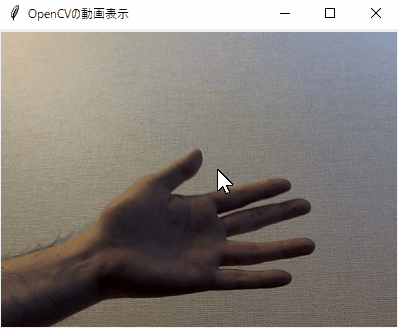
(処理結果)
※結果は画像データとしては得られず、上図の色付きの線で書いた部分の情報を取得します。
構文
findContours(image, mode, method[, contours[, hierarchy[, offset]]]) ->contours, hierarchy
image
輪郭抽出する画像データ
mode
輪郭構造の取得方法
method
輪郭座標の取得方法
(戻り値)contours
輪郭座標
(戻り値)hierarchy
輪郭の階層情報
image
輪郭抽出する画像データを指定します。
画像は8bitのグレースケールで、基本的に二値化された画像を指定します。
一部、32bit1チャンネルのデータ(ラベリングデータ)も指定可能です。
二値化されていない場合は、輝度値が0で無い部分に関しての輪郭情報を取得します。
mode
輪郭の階層情報の取得方法をRETR_EXTERNAL, RETR_LIST, RETR_CCOMP, RETR_TREE, RETR_FLOODFILL
最初に見つける輪郭が白の外側の輪郭となります。
そのため、入力画像は黒色背景の画像を指定します。
白色背景の画像を指定した場合、最初の輪郭は画像全体となります。
mode hierarchy
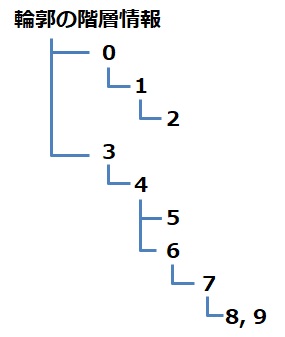
●RETR_TREE
輪郭の階層情報をツリー形式で取得します。
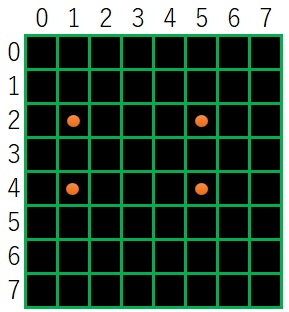
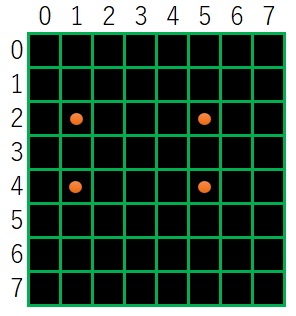
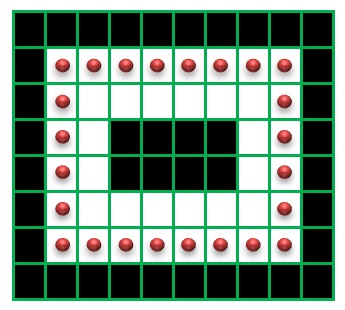
この輪郭の階層情報をというのは、下図を用いて説明します。
まず、一番外側の輪郭(白の領域の外側の輪郭)に0 3
0 1 3 4
さらに、
1 2 4 5 6
6 7
7 8 9
の輪郭があります。
この構造をツリーで表現すると、このようになります。
mode にRETR_TREE を指定するとhierarchy の中にこの階層構造が格納されます。
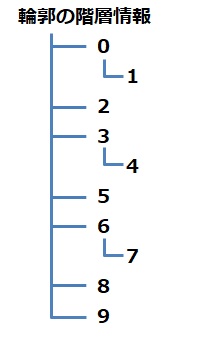
●RETR_CCOMP
白の輪郭(外側の輪郭)と黒の輪郭(内側の輪郭)の情報だけを取得し、白の輪郭のさらに内側の輪郭かどうか?の情報は失われます。
この構造をツリーで表現すると、このようになります。
●RETR_LIST 白(外側)、黒(内側)の区別なく、すべての輪郭を同じ階層として取得します。
この構造をツリーで表現すると、このようになります。
●RETR_EXTERNAL
一番外側の白の輪郭だけを取得します。
この構造をツリーで表現すると、このようになります。
method
輪郭を構成する点の座標の取得方法をCHAIN_APPROX_NONE, CHAIN_APPROX_SIMPLE, CHAIN_APPROX_TC89_L1, CHAIN_APPROX_TC89_KCOS
取得した座標は戻り値のcontoursに格納されます。
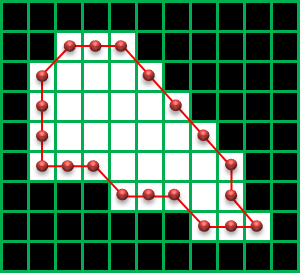
●CHAIN_APPROX_NONE
輪郭上のすべての座標を取得します。
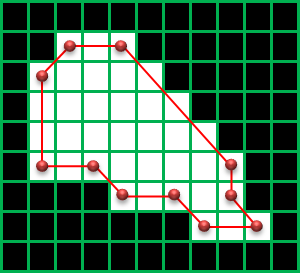
●CHAIN_APPROX_SIMPLE
縦、横、斜め45°方向に完全に直線の部分の輪郭の点を省略します。
●CHAIN_APPROX_TC89_L1, CHAIN_APPROX_TC89_KCOS
輪郭の座標を直線で近似できる部分の輪郭の点を省略します。
(戻り値)contours
輪郭上の座標を取得します。
実際にどのような座標を取得するかは、method
contoursのデータは以下のような配列となります。
contours[輪郭番号][点の番号][0][X座標, Y座標]
(戻り値)hierarchy
輪郭の階層情報を取得します。
取得する構造はmode
contoursのデータは以下のような配列となります。
hierarchy[0][輪郭番号][次の輪郭番号, 前の輪郭番号, 最初子供(内側)の輪郭番号, 親(外側)の輪郭番号 ]
となります。
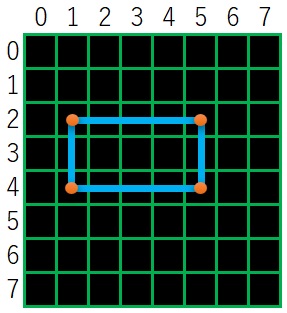
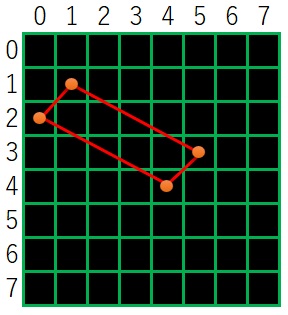
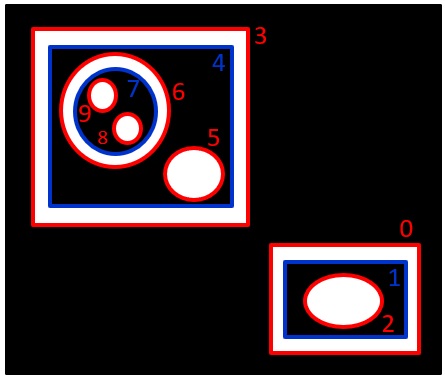
下図の例について説明します。
輪郭番号7 の親は6 で、最初の子供の番号は8 となります。
8 の次の輪郭番号は9 で、9 の前の輪郭番号は8 となります。
該当する輪郭番号が無い時は -1 になります。
上図の階層情報の例で言うと、
hierarchy[0][0] は [ 3, -1, 1, -1]
となります。
輪郭座標(contours)の注意点
contoursで取得できる座標は、白の領域を構成する外側の座標、もしくは内側の座標となります。
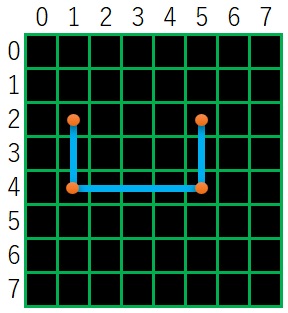
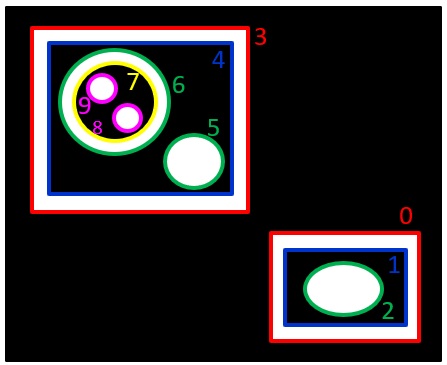
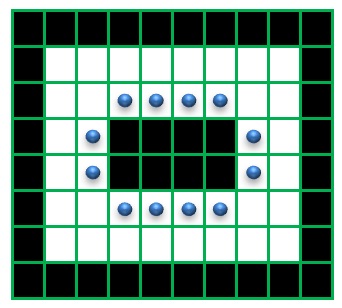
例えば、下図のような図形の輪郭座標を取得するとき、
白の輪郭を取得するときは、一番、外側の画素の座標(下図の赤い点)がcontoursに格納されます。
しかし、白の内側の黒の輪郭座標は、黒の画素の座標にはなりません
黒の輪郭座標は、輪郭を構成している黒の画素の4近傍の白の画素の座標
輪郭の描画
findContours()関数で取得した輪郭(contours)はdrawContours()関数を用いて描画します。
drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset]]]]]) ->image
image
描画先の画像データ
contours
輪郭座標
contourIdx
描画する輪郭の番号
color
描画の色を(b, g, r)のタプルで指定します
thickness
線幅
lineType
線の描画スタイルをFILLED, LINE_4, LINE_8, LINE_AAの中から指定します。
hierarchy
輪郭の階層情報を指定します。
maxLevel
輪郭をどの階層まで表示するかを指定します。
offset
サンプルプログラム
import cv2
# 8ビット1チャンネルのグレースケールとして画像を読み込む
img = cv2.imread("sample.bmp", cv2.IMREAD_GRAYSCALE)
contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE )
# 画像表示用に入力画像をカラーデータに変換する
img_disp = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
# 全ての輪郭を描画
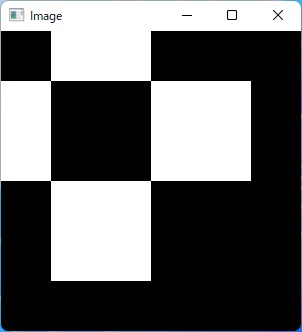
cv2.drawContours(img_disp, contours, -1, (0, 0, 255), 2)
# 輪郭の点の描画
for contour in contours:
for point in contour:
cv2.circle(img_disp, point[0], 3, (0, 255, 0), -1)
cv2.imshow("Image", img_disp)
# キー入力待ち(ここで画像が表示される)
cv2.waitKey()
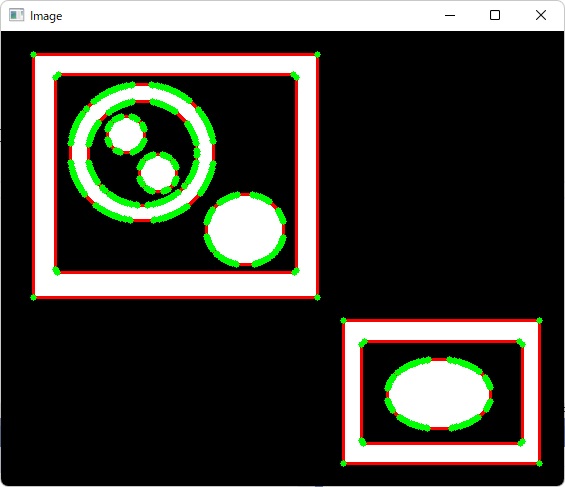
(実行結果)
関連記事
【OpenCV-Python】輪郭(contour)の面積(contourArea)
続きを見る 【OpenCV-Python】輪郭(contour)の矩形領域の取得
続きを見る 【OpenCV-Python】輪郭の周囲長(arcLength)
続きを見る